
Ticket #3972 (closed defect: fixed)
lib/vfs testsuite failures on illumos
| Reported by: | mnowak | Owned by: | zaytsev |
|---|---|---|---|
| Priority: | major | Milestone: | 4.8.33 |
| Component: | tests | Version: | master |
| Keywords: | Cc: | ||
| Blocked By: | Blocking: | #4495, #4591 | |
| Branch state: | merged | Votes for changeset: | committed-master |
Description
Running test suite from v4.8.22 on OpenIndiana 2018.10 (illumos kernel) with changeset from http://midnight-commander.org/ticket/3971#comment:1 I get following failures in the lib/vfs testsuite:
PASS: canonicalize_pathname PASS: current_dir FAIL: path_cmp FAIL: path_len FAIL: path_manipulations FAIL: path_serialize PASS: relative_cd PASS: tempdir PASS: vfs_adjust_stat PASS: vfs_parse_ls_lga PASS: vfs_path_from_str_flags FAIL: vfs_path_string_convert PASS: vfs_prefix_to_class PASS: vfs_setup_cwd PASS: vfs_split PASS: vfs_s_get_path PASS: path_recode PASS: vfs_get_encoding ============================================================================ Testsuite summary for /lib/vfs ============================================================================ # TOTAL: 18 # PASS: 13 # SKIP: 0 # XFAIL: 0 # FAIL: 5 # XPASS: 0 # ERROR: 0 ============================================================================ See tests/lib/vfs/test-suite.log ============================================================================
test-suite.log file is attached.
Let me know should you need information about the environment.
Attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History
comment:1 Changed 6 years ago by andrew_b
Well, I can see three kinds of test result in the attached log:
1) passed
2) failed
3) aborted
2) and 3) are charset related. What is your locale?
First of all I'm interesting aborted tests. Since I'm not an OpenIndiana? user I'm unable to reproduce these errors.
comment:2 Changed 5 years ago by andypost
I'm trying to enable tests on Alpinelinux and getting 2 failures in vfs_path_string_convert.c
Ref https://gitlab.alpinelinux.org/alpine/aports/merge_requests/3243
FAIL: path_len FAIL: vfs_path_string_convert
comment:3 Changed 2 months ago by zaytsev
- Owner set to zaytsev
- Status changed from new to accepted
Mentioned Alpine problems are due to musl iconv: #4495 .
Unfortunately, Cfarm doesn't have an Illumos / OpenIndiana host. I see that mc 4.8.31 is packaged. What is the current situation there, do the tests pass? Is there a development shell host one could use? Any build/test logs? What is the libc like, who provides iconv? Not sure if these failures are due to (to be fixed) mocking things, or iconv.
Maybe a good approximation is to check what is the situation on Solaris.
comment:4 Changed 2 months ago by mnowak
I am not involved with the project anymore, but you can get a Vagrant Box from https://app.vagrantup.com/openindiana/boxes/hipster.
comment:5 Changed 2 months ago by zaytsev
Thanks for the tip, do you happen to know if it's possible to download this somehow and import into UTM instead of setting up Vagrant? UTM is an interface for QEMU, so I'd need a qcow2 image and information about the machine configuration. Apparently recently a plugin for Vagrant was developed to use UTM behind the scenes, but if I don't have to install lots of stuff, that would be great...
comment:6 Changed 2 months ago by mnowak
The libvirt provider of the Box might be a QCOW2 underneath, but likely won't boot as such if extracted and imported.
There are also installation images https://openindiana.org/downloads/; even the minimal image has a small runtime environment with shell, but if you need to install a package to debug things, you'd rather install the whole OS and go from there.
comment:7 Changed 2 months ago by zaytsev
Thanks again! That looks good so far. Is there any way to know how the machine is configured? Vargantfile has only the following inside:
{"architecture":"amd64","disks":[{"format":"qcow2","path":"box_0.img"}],"provider":"libvirt"}
Like memory, CPU, devices...
comment:8 Changed 2 months ago by mnowak
The configuration is likely sourced from https://github.com/OpenIndiana/oi-packer.
comment:9 Changed 2 months ago by zaytsev
Perfect, I've got it to work - the configuration is here:
https://github.com/OpenIndiana/oi-packer/blob/master/hipster.pkr.hcl
Default PC, 4G RAM, AMD64.
Sadly, everything is extremely slow on ARM, but apparently OI doesn't support ARM natively, so emulation is the only option.
But how do I get in on the console? jack/jack & root/openindiana are not working!
comment:10 Changed 2 months ago by mnowak
Try, root/vagrant https://github.com/OpenIndiana/oi-packer/blob/master/hipster.pkr.hcl#L16?
comment:11 Changed 2 months ago by zaytsev
Hey, not sure how I have missed it. You were of great help, thank you! I guess I should add some notes on how to test on OpenIndiana on our wiki. I was still able to reproduce test failures. There are two types of problems:
- Relates to our vfs scripts and test suite not compatible with ksh, because of the local keyword - see attached patch - seems uncomplicated to fix
- Everything that has to do with charset conversion fails - with --disable-charset all test pass (surprisingly!) - which seems to be the same issue as with Alpine / musl.
The charset stuff is annoying, because to my understanding we are actually not using it directly, but pulling it from glib, so either we do something wrong, or glib iconv is broken on these platforms.
I guess I need to look into small reproducer. In the worst case we should include it in autoconf tests and disable charsets if this test fails, because then mc is not going to work correctly.
comment:12 Changed 2 months ago by mnowak
You are welcome. iconv might be different on illumos distributions like OpenIndiana? (source from https://github.com/illumos/illumos-gate/tree/master/usr/src/cmd/iconv) and might do a few things differently to more common GNU libinconv.
comment:13 follow-up: ↓ 16 Changed 2 months ago by zaytsev
I have tested iconv on the command line and it seems to convert between UTF-8 and KOI8-R used in the tests just fine. All aliases also available. I was even able to read the file in translation mode with mcview coming from the shipped mc! So at least for that the conversions are working correctly.
So I started reading path_len.c and following the functions with HAVE_CHARSET, and I actually don't quite get how it works. Apparently the idea was that the elements of the path are converted from terminal encoding into whatever #enc says they should be encoded in memory, and the encoding is also set to what enc says:
https://github.com/MidnightCommander/mc/blob/master/lib/vfs/vfs.c#L170
But then apparently it was supposed to stay UTF-8 (or rather terminal encoding) in vpath->str when all elements are joined again?
For me on macOS this conversion doesn't do anything though (WHAT?!), it seems that the element stays encoded as UTF-8. But apparently as there is a bug in the conversion back, which also doesn't happen, so the end result is correct and the test pass.
It seems that on OpenIndiana/Illumos and Alpine/musl it actually DOES the conversion to KOI8-R as intended, but due to missing conversion back the test fails.
Andrew, can you help, at least tell me how it was supposed to work before I debug further? This is very confusing.
comment:15 Changed 2 months ago by zaytsev
On Illumos: term_encoding: 646 (!?)
$ iconv -l
The following are all supported code set names. All combinations
of those names are not necessarily available for the pair of the
fromcode-tocode. Some of those code set names have aliases, which
are case-insensitive and described in parentheses following the
canonical name:
5601,
646 (ASCII, US-ASCII, US_ASCII, USASCII),
With the following patch:
diff --git a/tests/lib/vfs/path_len.c b/tests/lib/vfs/path_len.c
index 6bab6f551..24beca8ac 100644
--- a/tests/lib/vfs/path_len.c
+++ b/tests/lib/vfs/path_len.c
@@ -42,7 +42,7 @@
static void
setup (void)
{
- str_init_strings (NULL);
+ str_init_strings ("UTF-8");
vfs_init ();
vfs_init_localfs ();
The tests work on Illumos. But for any single bit (KOI8-R or ASCII) seems to break.
On macOS: term_encoding: US-ASCII, but also forcing "UTF-8" works.
comment:16 in reply to: ↑ 13 Changed 2 months ago by andrew_b
Replying to zaytsev:
Andrew, can you help, at least tell me how it was supposed to work before I debug further? This is very confusing.
Sorry :-(
comment:17 Changed 2 months ago by zaytsev
- Cc slavazanko added
I see, so the whole VFS magic including recoding was Slava's work, and you don't know how this #enc: stuff was actually supposed to work? Slava, are you alive :) ? Can you say something?
comment:18 Changed 2 months ago by zaytsev
So I traced the functions again on macOS, and I was initially wrong about conversion not happening there which confused me. Everything is working as expected (?):
- vpath = vfs_path_from_str_uri_parser (path);
- Here, deep inside, the conversion from UTF-8 to KOI8-R in-memory representation is happening in _vfs_translate_path
- vpath->str = vfs_path_to_str_flags (vpath, 0, flags);
- Here the opposite conversion from KOI8-R memory representation to UTF-8 is happening using str_vfs_convert_from
It seems that there is some problem with vfs_path_to_str_flags on Illumos, which apparently doesn't have to do with iconv, but with detecting terminal encoding and the need to convert back. Or maybe the conversion fails and this is not handled correctly. In any case, the problem is that the conversion from UTF-8 to KOI8-R happens correctly in vfs_path_from_str_uri_parser, but the conversion back to UTF-8 doesn't happen.
If I force terminal encoding to UTF-8 with str_init_strings ("UTF-8") as shown above, then both conversions are happening correctly like on macOS.
I wonder if I can get any further with a debugger...
comment:19 Changed 2 months ago by zaytsev
gdbserver is not supported on Solaris, and gdbgui needed fixing:
- https://github.com/miguelgrinberg/Flask-SocketIO/pull/2088
- https://github.com/cs01/gdbgui/pull/491
And best of all, the tests pass under graphical debugger - probably because it's run inside Python and stuff is set to UTF there :(
I have the feeling that g_iconv_open (codeset, from_enc) where codeset="646" and from_enc="KOI8-R" in strutil.c:269 returns something that doesn't do anything, which is weird, because the conversion in the forward direction works.
comment:20 follow-up: ↓ 21 Changed 2 months ago by zaytsev
I think I've figured out what the problem is with Illumos and Alpine. The issues are not exactly the same, but the root cause is the same.
In the VFS library we have conversions that go in two directions:
- From terminal encoding to the desired encoding
- Handled by the vfs_translate_path function
- From desired encoding to terminal encoding
- Handled by str_vfs_convert_from function
Both functions return estr_t, which can be ESTR_SUCCESS, ESTR_PROBLEM (some characters could not be translated, so it's not possible to reverse the operation) and ESTR_FAILURE (conversion impossible due to wrong / unsupported encoding).
The result of the forward conversion vfs_translate_path is somehow checked and returns a NULL pointer on failure, which is supposed to be checked (hopefully?), but on problems it doesn't do anything and just continues.
The result of the backward conversion (str_vfs_convert_from) is simply ignored!
path_len test
This test is started with str_init_strings (NULL), which means US-ASCII on macOS and equivalents elsewhere. The HAVE_CHARSET part contains a raw UTF-8 string that should be recoded as KOI8-R for the file system.
Linux and macOS
iconv just interprets the UTF-8 string as bytes of US-ASCII and "converts" them from bytes of KOI8-R without changing anything.
The problem happens during the conversion from KOI8-R to US-ASCII and is signaled as ESTR_PROBLEM, but it's not a hard error, just some characters can't be translated. And what iconv does is just leave the string as it is.
Since the result of the backward conversion is ignored, everything matches.
Solaris
Here iconv actually decides to do a forward conversion because it can and it's valid, even though it probably shouldn't. So the path element is now a valid KOI8-R string.
The backward conversion from KOI8-R to US-ASCII fails, but iconv leaves the string as it is and ignores the result, so the KOI8-R string is returned.
The length obviously doesn't match and the test fails.
Alpine
Similar to Solaris, but instead of returning the string unchanged, iconv returns an empty string, so path ends up being /#enc:KOI8-R and the assertion fails:
Assertion 'actual_length == data->expected_length' failed: actual_length == 12, data->expected_length == 38
Conclusion
This particular test is simply broken and only works on Linux and macOS by (bad) luck. It should be initialized with str_init_strings ("UTF-8") and this would make the test work correctly on all systems.
I haven't analyzed other tests, but probably they can be fixed somehow.
My question is, what do we do about error handling? It doesn't sound like a good idea to just ignore problems. At the very least, it leads to buggy tests working by accident without anyone noticing. But there are also segfaults on Alpine.
I think maybe it was designed that way because the whole recoding story was for like Linux (KOI8-R) systems accessing Windows FTP (CP1251) with wrong encoding returned or something, so in the worst case the errors mean the file list is garbage or something, and there was actually no intention to propagate errors.
I think we should at least not ignore ESTR_FAILURE on reverse conversion and return a string of ??? of the same length as the input one, so nothing segfaults.
I'm also not sure about returning a NULL pointer on forward conversion. I see some NULL checks, but many seem to be missing. Maybe also return a string of ??? instead?
We can then test for invalid conversions.
Andrew, what do you think?
comment:21 in reply to: ↑ 20 Changed 2 months ago by andrew_b
Replying to zaytsev:
This particular test is simply broken and only works on Linux and macOS by (bad) luck. It should be initialized with str_init_strings ("UTF-8")
Because test strings are in UTF-8?
and this would make the test work correctly on all systems.
My question is, what do we do about error handling? It doesn't sound like a good idea to just ignore problems.
Definitely, an error handling should be done.
I think we should at least not ignore ESTR_FAILURE on reverse conversion and return a string of ??? of the same length as the input one, so nothing segfaults.
I'm also not sure about returning a NULL pointer on forward conversion. I see some NULL checks, but many seem to be missing. Maybe also return a string of ??? instead?
Probably, in cases of ESTR_FAILURE return of an input string is a workable solution. But if it hides a conversion problem from the caller, it's better to return NULL and a caller should decide to do then.
We can then test for invalid conversions.
comment:22 Changed 2 months ago by zaytsev
Because test strings are in UTF-8?
Yes.
Suppose you want to test the correctness of the conversions from the terminal encoding to the desired encoding and back at a very superficial level. You need to provide a path that will be encoded differently than the terminal encoding, but the conversion should be lossless.
For example, you can provide the test string in UTF-8 (which will be your terminal encoding) and say that a part of it should be converted to KOI8-R: /#enc:KOI8-R/тестовый/путь. You can now check that after the roundtrip the path has the correct length in bytes (38). You should also check that /тестовый/путь takes 14 bytes in KOI8-R and not 26 bytes. But this was never checked, and so no one has found out that the test is wrong.
The thing is, you have to do str_init_strings ("UTF-8") for the code to work correctly (UTF-8 -> KOI8-R -> UTF-8). If you do str_init_strings (NULL), it will assume that the terminal encoding is ASCII and your string is in ASCII, but it's actually in UTF-8. What happens then depends on how exactly iconv fails, but because we don't do proper error handling, the roundtrip actually works on Linux and macOS as no conversion happens and the raw bytes are just preserved. On Solaris and musl, different things happen, but at least one of the two conversions fails.
So we can either fix the test by adding a missing assertion and setting the encoding to UTF-8, which it is, and then it will work everywhere. Or we can choose a different pair of encodings.
For example, hardcode bytes to CP1251 and do a CP1251 -> KOI8-R -> CP1251 conversion. But this might not be so good for length checks, because both are singlebyte encodings. Unfortunately, the only multibyte encoding we support is UTF-8, because the whole path handling depends on ASCII symbols like / being encoded as single-byte ASCII. So I think it's fine to keep UTF-8. It's actually a good test, and single byte conversions should be tested elsewhere, like `vfs_path_string_convert'.
I have started a branch to fix the tests. Unfortunately, the following tests still need to be investigated (some of them may fail due to broken mocks, see #4584):
FAIL: path_cmp FAIL: path_manipulations FAIL: path_serialize FAIL: vfs_path_string_convert FAIL: edit_complete_word_cmd
comment:23 Changed 2 months ago by zaytsev
path_cmp - fixed in the same way as path_len.
path_manipulations & path_serialize have the same problem: for some reason I don't understand yet, #enc:KOI8-R is dropped when manipulating the path (in vfs_path_append_vpath_new and so vfs_path_to_str_flags).
Setting terminal encoding to UTF-8 or a valid Cyrillic encoding like CP1251 fixes the tests.
comment:24 Changed 2 months ago by zaytsev
Ok, I think I know why this happens. On Solaris, g_iconv_open ("ASCII", "KOI8-R") fails because this conversion is considered invalid. On macOS and apparently Linux, this converter can be created, and as long as the compatible subset is given as strings, it even works.
The problem is the lack of error handling in the str_crt_conv_from function in the VFS. At other call sites there are some cases where errors are handled. But I don't know how to add error handling there. My idea is to keep fixing tests and then make a list of places where error handling is missing, so this went unnoticed.
comment:25 follow-up: ↓ 26 Changed 2 months ago by zaytsev
vfs_path_string_convert segfaults, because the NULL pointer returned in vfs_translate_path_n is simply ignored and later explodes as element->path is NULL:
$ pstack core core 'core' of 10170: ./vfs_path_string_convert 0000000000427cd0 vfs_path_to_str_flags () + 15f2 00000000004280b5 vfs_path_from_str_flags () + b2 000000000042b05d test_from_to_string_fn () + 3d 00007fffac43945c srunner_run_tagged () + 55c 0000000000424808 mctest_run_all () + 5f 000000000042b510 main () + b3 0000000000424687 _start_crt () + 87 00000000004245e8 _start () + 18
edit_complete_word_cmd segfaults due to missing error handling:
$ pstack core core 'core' of 19717: ./edit_complete_word_cmd 00007fffaf379c05 iconv_close (ffffffffffffffff) + 15 00000000004f1af9 str_close_conv () + 28 00000000004ea422 str_nconvert_to_display () + 90 00000000004656a9 edit_collect_completion_from_one_buffer () + 2cd 0000000000465972 edit_collect_completions () + 1c4 0000000000466104 edit_complete_word_cmd () + 2d5 0000000000455319 test_autocomplete_fn () + c1 00007fffac43945c srunner_run_tagged () + 55c 00000000004545e8 mctest_run_all () + 5f 000000000045583e main () + 8a 0000000000454487 _start_crt () + 87 00000000004543e8 _start () + 18
comment:26 in reply to: ↑ 25 Changed 2 months ago by andrew_b
Replying to zaytsev:
edit_complete_word_cmd segfaults due to missing error handling:
00000000004ea422 str_nconvert_to_display () + 90
I've added a commit with fix of that.
comment:27 follow-up: ↓ 29 Changed 2 months ago by zaytsev
I've added a commit with a fix for this.
Wow, with your change, the test passes when I remove my UTF-8 commit!
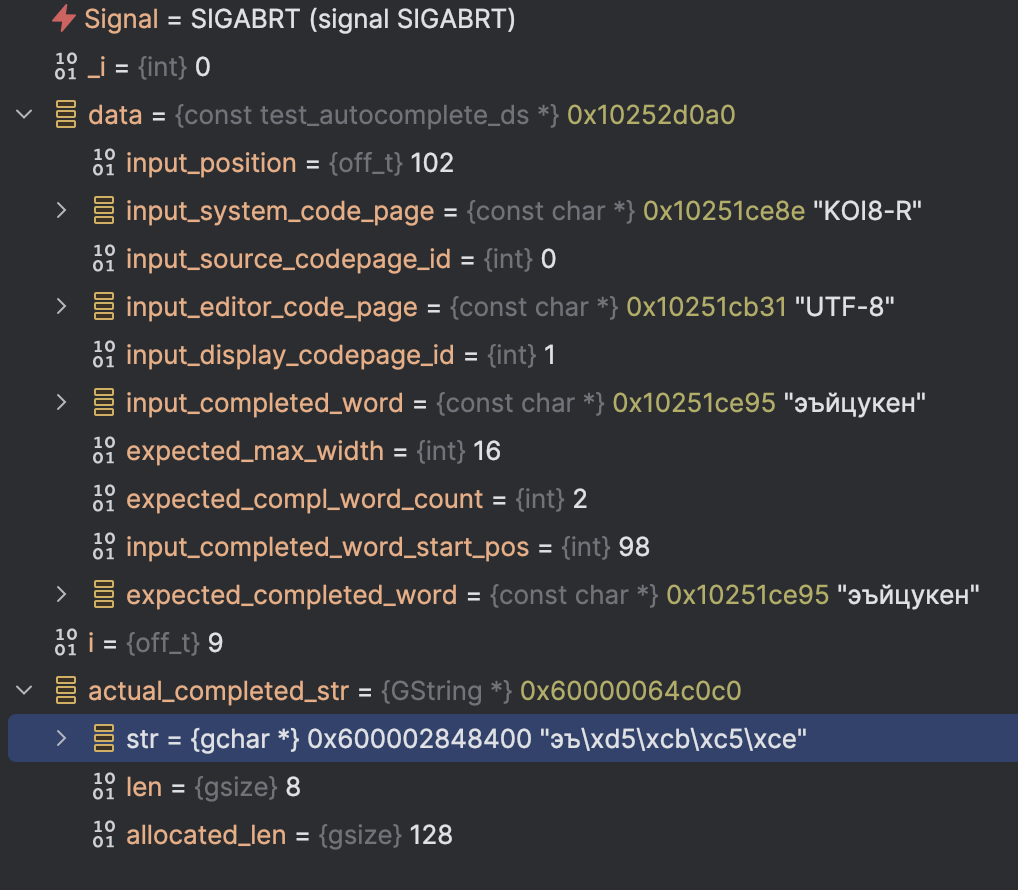
However, if the terminal encoding is initialized as UTF-8, the test fails (see screenshot for a better view - expected completion is "эъйцукен", but actual completion is "эъ" in UTF-8 + "йцукен" in KOI8-R). I can reproduce this on Mac as well by changing to str_init_strings ("UTF-8").
I think this is of the same nature as other problems - with UTF-8 in the loop, the conversion of "йцукен" to KOI8-R (which probably shouldn't be there) works and the test fails, but if some other encoding is used, the string is simply copied without conversion and nobody notices because of the lack of error handling.
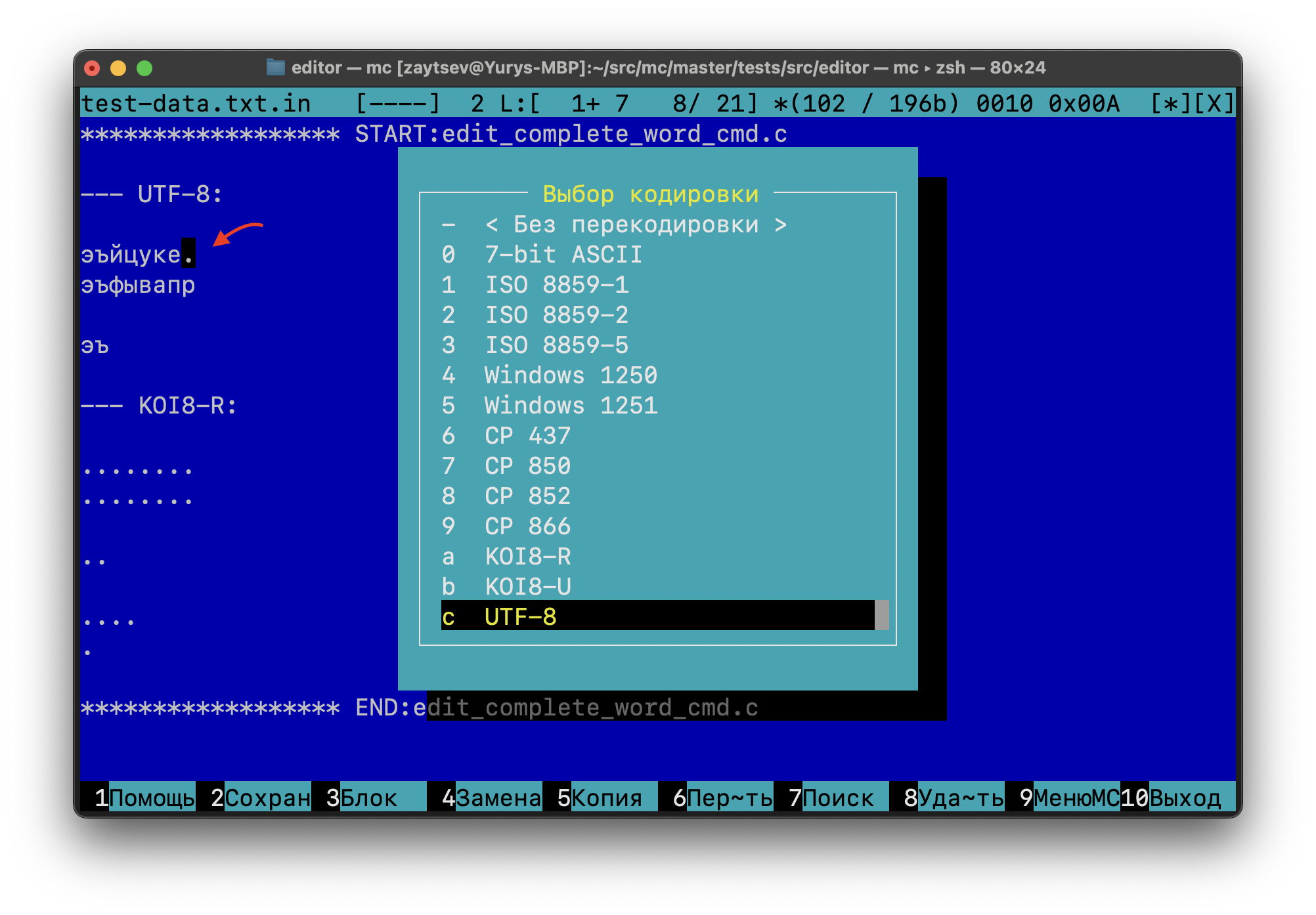
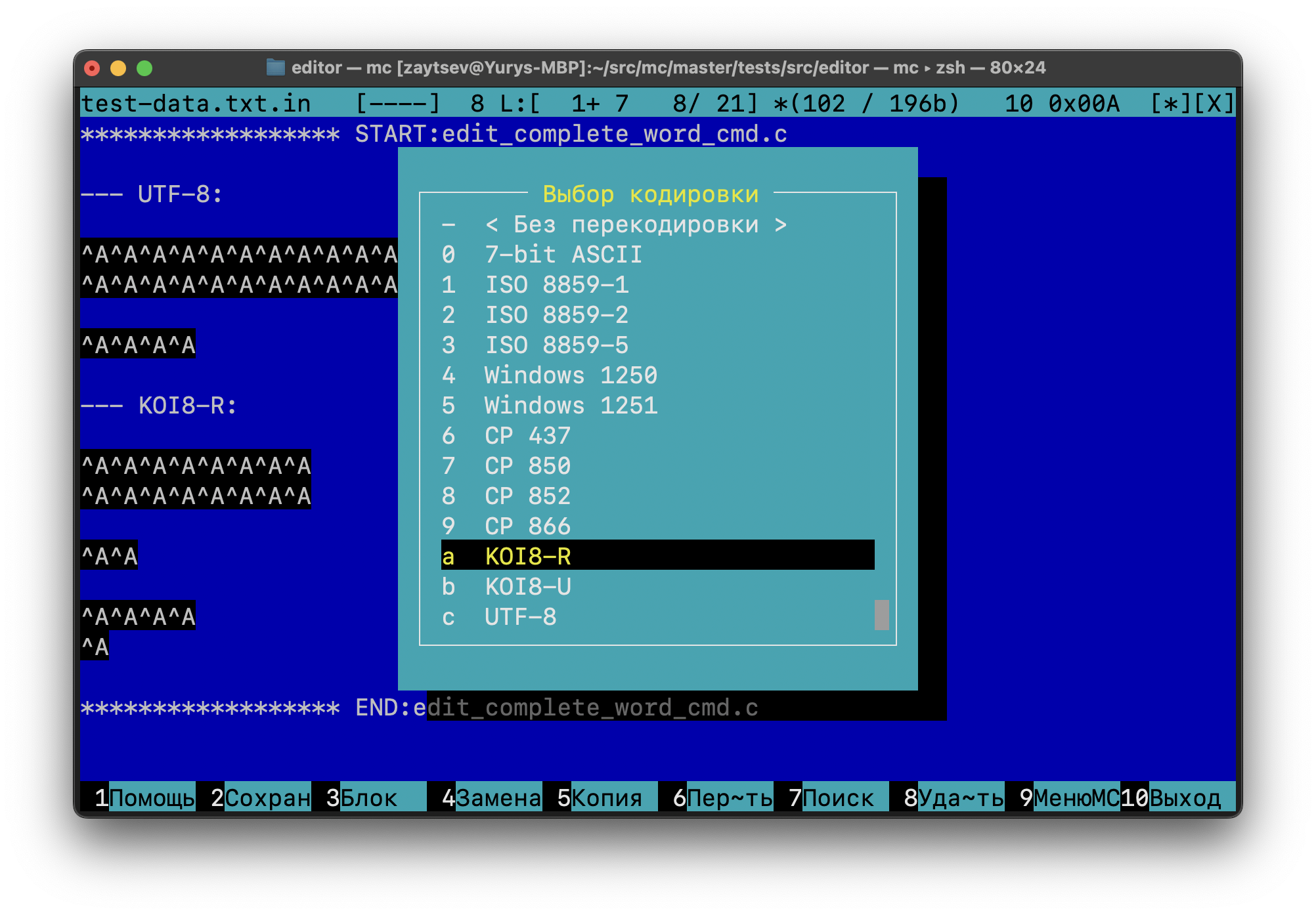
I also tried running mc in a CP866 terminal, and two screenshots are attached. It seems that there are indeed conversion/display bugs in the editor. When I open the file from the test, it looks about right with no translation, with UTF-8 it looks "sort of" right, but there is some display bug, and with "KOI8-R" translation everything is wrong.
Unfortunately I'm completely lost with the editor stuff. Maybe if you could help debug this, we can open a separate ticket for it, as it seems to be a general problem with encoding translation in the editor...
comment:28 Changed 2 months ago by zaytsev
Regarding your changes to str_nconvert_to_display and str_nconvert_to_input: this means that if conversion is not possible, it is silently not done.
That's why I don't know how to implement error handling myself. I can't throw an exception that will propagate the call stack, and if I just return empty or unchanged strings, no one will notice that the conversion didn't work. If I return NULL pointers, then the caller has to check, but callers are usually pretty deep and can't display user messages or anything.
So maybe it is better to return strings of the same size as the input, but made of "????" - at least then the problem will be noticed? At the moment I think that skipping the conversion as you did is what "fixed" the test, but the conversions that happen might be wrong - see the strange way it fails with "UTF-8".
comment:29 in reply to: ↑ 27 Changed 2 months ago by andrew_b
Replying to zaytsev:
with UTF-8 it looks "sort of" right, but there is some display bug,
If you try input the cyrillic 'Н' or 'н' (Unicode 0x41d and 0x43d respectively) you can see the dot as in screenshot (this looks like this character is non-printable). All other letters are displayed correctly. This is very strange.
and with "KOI8-R" translation everything is wrong.
Can't confirm. Looks correct for me. Locale is ru_RU.ibm866 and IBM866 in mc.charsets.
But can confirm if locale is ru_RU.ibm866 and CP866 in mc.charsets.
Seems the same name (IBM866 or CP866) must be as in locale as in mc.charsets.
Unfortunately I'm completely lost with the editor stuff. Maybe if you could help debug this, we can open a separate ticket for it, as it seems to be a general problem with encoding translation in the editor...
Ok.
comment:30 follow-up: ↓ 31 Changed 2 months ago by zaytsev
Seems the same name (IBM866 or CP866) must be as in locale as in mc.charsets.
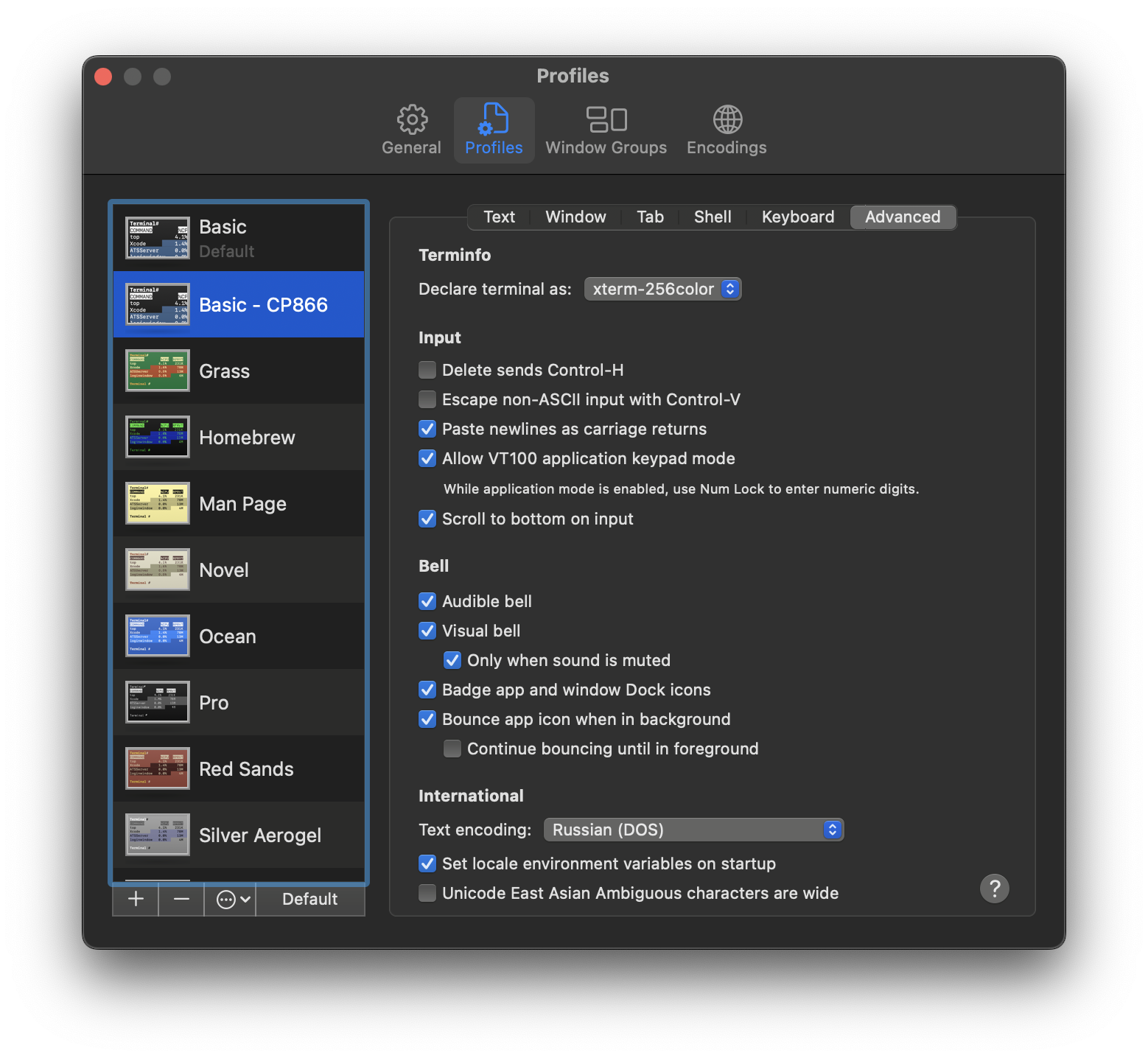
You are right! I don't have IBM866 on Mac, so I started mc as follows and set the Terminal to Russian (DOS) - see screenshot.
zaytsev@Yurys-MBP ~ % locale -a | grep 866 ru_RU.CP866 zaytsev@Yurys-MBP ~ % export LANG=ru_RU.CP866 LC_ALL=ru_RU.CP866 zaytsev@Yurys-MBP ~ % locale LANG="ru_RU.CP866" LC_COLLATE="ru_RU.CP866" LC_CTYPE="ru_RU.CP866" LC_MESSAGES="ru_RU.CP866" LC_MONETARY="ru_RU.CP866" LC_NUMERIC="ru_RU.CP866" LC_TIME="ru_RU.CP866" LC_ALL="ru_RU.CP866"
After I changed IBM866 to CP866 in the charsets, the translation to KOI8-R started working correctly, but I still have the weird non-printable character for UTF-8, which is not right.
So do you have IBM866 on your system and no CP866? If yes, then I think we have a rather annoying problem, because we can't make an entry that works on all systems, unless we add a concept of aliases :( In any case, since there is no error handling, instead of showing the error message or interacting with the user somehow, mcedit just does a completely wrong translation...
Maybe when the main translation converters are initialized, if iconv returns an invalid converter, we can alert the user?
comment:31 in reply to: ↑ 30 Changed 2 months ago by andrew_b
comment:32 follow-up: ↓ 34 Changed 2 months ago by zaytsev
Yes. This is glibc.
I see, you are right: glibc only has IBM866 - I think this is where it all comes from. I tested on the latest Fedora: it doesn't have 866 locales, so I generated them:
root@fedora:~# localedef --no-archive --inputfile=ru_RU --charmap=IBM866 ru_RU.cp866 root@fedora:~# localedef --no-archive --inputfile=ru_RU --charmap=IBM866 ru_RU.ibm866 root@fedora:~# locale -a | grep 866 ru_RU.cp866 ru_RU.ibm866 root@fedora:~# iconv -l | grep 866 866// 866NAV// CP866// CP866NAV// CSIBM866// IBM866// IBM866NAV//
When I start mc with these locales and terminal set to 866, translation works regardless of the entry in mc.charsets. The only thing that doesn't work reproducibly is the Russian н, which is shown as unprintable.
What is your Linux system and what does iconv say? Is it possible that you don't have the CP866 alias in iconv?
vagrant@openindiana:~/src/mc/tests/src/editor$ iconv -l | grep 866
CP866 (CP866, CP-866, CP_866, 866),
IBM-866,
zaytsev@Yurys-MBP ~ % iconv -l | grep 866
CP866 866 CSIBM866 IBM866 MSCP866
On Solaris it doesn't even have IBM866 as an alias, which is why the tests segfaulted, on Mac it has an alias, but then the same strange thing happens as on your system.
The change to IBM866 in our code from CP866 happened in changeset:56d95515 without any explanation.
comment:33 Changed 2 months ago by zaytsev
Actually, I wonder why the values in mc.charset and their correspondence to the current system locale matter at all. I thought they were just for the transcoding menu, to map iconv-accepted conversion names to human-readable descriptions. It sounds completely wrong for them to affect anything else. If we could fix this, we could use aliases that work on all systems.
comment:34 in reply to: ↑ 32 Changed 2 months ago by andrew_b
Replying to zaytsev:
When I start mc with these locales and terminal set to 866, translation works regardless of the entry in mc.charsets. The only thing that doesn't work reproducibly is the Russian н, which is shown as unprintable.
I've created ru_RU.cp866:
# localedef --no-archive --inputfile=ru_RU --charmap=IBM866 ru_RU.cp866
In ru_RU.CP866 locale and CP866 terminal character encoding:
- CP866 in mc.charsets: translation to KOI8-R doesn't work as in your Screenshot 2024-09-13 at 12.37.54
- IBM866 in mc.charsets: translation to KOI8-R works correctly.
In ru_RU.IBM866 locale and CP866 terminal character encoding:
- CP866 in mc.charsets: translation to KOI8-R doesn't work
- IBM866 in mc.charsets: translation to KOI8-R works correctly.
With CP866 in mc.charsets, translation to KOI8-R doesn't work in both cases. Very strange.
What is your Linux system
and what does iconv say? Is it possible that you don't have the CP866 alias in iconv?
$ iconv -l | grep 866 866// 866NAV// CP866// CP866NAV// CSIBM866// IBM866// IBM866NAV//
comment:35 Changed 2 months ago by andrew_b
Regardless of 866 locale name (ru_RU.CP866 or ru_RU.IBM866), nl_langinfo(CODESET) returns IBM866 (glibc doesn't have CP866).
comment:36 follow-up: ↓ 37 Changed 2 months ago by zaytsev
Very strange.
I think I'm beginning to understand why this happens. Your hunch about nl_langinfo is correct.
In check_codeset, the result of str_detect_termencoding is compared to the values in the mc.charset file to set display_codepage. In your case it's IBM866 and in mine it's CP866. If there is no match, the result is ASCII. If display_codepage is set to a wrong value, things break - but no warning is shown to the user.
https://github.com/MidnightCommander/mc/blob/master/src/main.c#L103
It's possible to find the same name or alias for important encodings on different platforms that are supported by all iconvs (like CP866 or CP1251), but charmap filenames are incompatible between glibc and other libcs such as BSD, Solaris, AIX and musl.
However, mc relies on charmap names instead of iconv names because it wants to display "friendly" names of encodings in dialogs, and this requires a key. This is also why a hack for ANSI1251 was added for Solaris in the past.
I wonder how we can solve this problem:
- Is it possible to decouple display_codepage & source_codepage from mc.charsets? I guess not :(
- Maybe we could introduce aliases to mc.charset (and change the format to something that can be automatically parsed by glib to throw away old complicated custom parsing code)?
- Another (bad?) idea is to make entries in mc.charsets like this:
IBM866 CP 866 (Linux) CP866 CP 866 (Mac, Solaris)
Any thoughts on what we should do? Also, I'm not sure if it's possible to show a warning in check_codeset...
For letter "Н" I still have no explanation :(
comment:37 in reply to: ↑ 36 Changed 2 months ago by andrew_b
Replying to zaytsev:
Another (bad?) idea is to make entries in mc.charsets like this:
What about aliases: comma-separated items in 1st column:
IBM866,CP866 CP 866 CP1251,Windows-1251 Windows 1251
For letter "Н" I still have no explanation :(
src/editor/editdraw.c:606: get utf-8 char from editbuffer.
src/editor/editdraw.c:732: convert utf-8 char to 8-bit one.
src/editor/editdraw.c:765: mis-interpretate 8-bit char as gnichar and pass it to g_unichar_isprint().
I think I've fixed that. Patch edit_printable.patch is attached: the (edit->utf8) branch (src/editor/editdraw.c:763) was removed.
comment:38 Changed 2 months ago by zaytsev
What about aliases: comma-separated items in 1st column
Yes, we can do that. Rewrite the parser with g_data_input_stream_read_line & g_strsplit :) But what about the data structure? Currently it's an array of codepage_desc. If we don't change it, we might as well add additional entries like I suggested.
If we do change it (support aliases), then we can do something like add an aliases GArray, but then we have to be very careful to make sure that whenever encoding comes from "outside", aliases are considered and it's normalized to an id. The first alias (id) will then be what iconv accepts everywhere, and the next aliases are charmap names on different systems.
Patch version 2
Wow! Will have a look. I was thinking, maybe introduce a constant like UNPRINTABLE for '.'?
comment:39 Changed 2 months ago by zaytsev
I looked a bit more into implementing aliases support. As I suggested, there are two ways to do it:
- Parse file into existing data structure (id & name)
- Parse file into new data structure (id, aliases & name)
I tried the second option, which I think is the only one that makes things better, but it just seems too crazy:
My understanding is that we need to check all usages of get_codepage_index and get_codepage_id and the variables where the results are stored. Every place where some comparisons are done needs to be replaced with a new function like codepage_equals which takes the aliases into account. I think it's about ~100 places to check.
So I tried the first option just to see how it feels and came up with a patch (I know it's dirty, just to show what I mean!). I'm not sure if it makes things any better compared to manual entries in the file. You need some kind of way to disambiguate the descriptions for aliases, so I added the id in parentheses. None of this feels like it's worth it... except maybe if you like my gio / glib conversion instead of the usual C-style manual parsing.
P.S. I also threw away the default thing, which I think was never used.
comment:40 Changed 2 months ago by andrew_b
Aliases mean that we will have several codepages assigned to one menu item. We don't want several menu items with same text, are we? If one menu item will cover several codepages we should somehow try them one by one to found workable convertor.
comment:41 Changed 2 months ago by zaytsev
Aliases mean that we will have several codepages assigned to one menu item.
Yes, this is the option (2) described in comment:39. But how to do this? Do you have any idea how to avoid going through all the call sites? I will not manage to rewrite this in several months. Parsing turned out to be the "easy" part...
Maybe we can do more hacks like the Solaris one, even though it's disgusting? I think not many code pages are affected. I have started to make a list of differences between platforms.
comment:43 Changed 8 weeks ago by zaytsev
- Cc slavazanko removed
- Branch state changed from no branch to on review
- Milestone changed from Future Releases to 4.8.33
Branch: 3972_fix_illumos
Initial changeset:c4a29da290dd6ebf6fb88071f9e6456820e92f8c
I have rebased everything, cleaned up the patches and went for the encoding name detection. The other options are just an insane amount of work with the current code base. Follow-up ticket is #4591. Maybe one day someone could have a look.
comment:44 Changed 7 weeks ago by zaytsev
It seems that there is still one test, that now fails on Linux :( The paths are dropped due to missing error handling as explained in #4591.
FAIL: vfs_path_string_convert
comment:45 follow-up: ↓ 46 Changed 7 weeks ago by zaytsev
The test passes on Linux if I add CP866 in addition to IBM866 to mc.charsets for tests.
IBM866 CP 866 CP866 CP 866
What is this evil magic again :( I thought that iconv translations were independent of the display stuff, but somehow there is still a relationship.
comment:46 in reply to: ↑ 45 Changed 7 weeks ago by andrew_b
Replying to zaytsev:
The test passes on Linux if I add CP866 in addition to IBM866 to mc.charsets for tests.
IBM866 CP 866 CP866 CP 866What is this evil magic again :( I thought that iconv translations were independent of the display stuff, but somehow there is still a relationship.
The test is passed if encoding in mc.charsets is the same as in vfs_path_string_convert.c.
sed -i -e 's/CP866/IBM866/' vfs_path_string_convert.c
makes the test passed with IBM866 in mc.charsets.
comment:47 Changed 7 weeks ago by zaytsev
The test is passed if encoding in mc.charsets is the same as in vfs_path_string_convert.c.
Yes, I understand that. My question is WHY?
I found the answer for initialisation (codeset must match), and figured it's impossible for me to fix without rewriting mc. But I was hoping that conversions would be independent of this list of encodings: The iconv function works with both CP866 and IBM866.
The only suspicious place I've found is is_supported_encoding, but when I set it to return true it still doesn't work. There seems to be some other hidden connection.
comment:48 Changed 6 weeks ago by zaytsev
It is the is_supported_encoding function! Apparently the source files were not rebuilt properly the last time I checked, so this confused me. This function determines if encoding is supported by looking at the charsets table, which I think is wrong. My idea would be to try creating a converter with iconv instead, and if it works - great, if not, the encoding is not supported.
diff --git a/lib/charsets.c b/lib/charsets.c
index ccaf4f6ae..67553fa62 100644
--- a/lib/charsets.c
+++ b/lib/charsets.c
@@ -267,17 +267,10 @@ get_codepage_index (const char *id)
gboolean
is_supported_encoding (const char *encoding)
{
- gboolean result = FALSE;
- guint t;
-
- for (t = 0; t < codepages->len; t++)
- {
- const char *id;
-
- id = ((codepage_desc *) g_ptr_array_index (codepages, t))->id;
- result |= (g_ascii_strncasecmp (encoding, id, strlen (id)) == 0);
- }
-
+ GIConv coder = str_crt_conv_from (encoding);
+ gboolean result = (coder != INVALID_CONV) ? TRUE : FALSE;
+ if (result)
+ str_close_conv (coder);
return result;
}
But I have the next problem: canonicalize_pathname test fails :(
/b/#enc:utf-8/../c != /c /b/c/#enc:utf-8/.. != /b
Other test cases pass...
comment:49 Changed 6 weeks ago by zaytsev
This seems to be a bug in the code: the old version of is_supported_encoding would ignore everything in the encoding name if a partial match was found. The new version, of course, wants a full match. The code in these test cases passes utf-8/../c as the encoding name, and the new function returns false.
I think a partial match is a bad idea. It could allow old code to accept completely invalid encoding names like koi8-rus. It wouldn't be removed from the path even though it's invalid and unsupported.
comment:50 follow-up: ↓ 51 Changed 6 weeks ago by zaytsev
Suggested fix in changeset:3ef535f8b48e850f7ef465c2dee36e9cde3f55b6 . Please review.
comment:51 in reply to: ↑ 50 Changed 6 weeks ago by andrew_b
Replying to zaytsev:
Suggested fix in changeset:3ef535f8b48e850f7ef465c2dee36e9cde3f55b6 . Please review.
Fixes:
- coding style;
- memory leaks in canonicalize_pathname_custom() due to usage of vfs_get_encoding();
vfs_get_encoding() was move to the "public functions" section of file.
comment:52 Changed 6 weeks ago by zaytsev
Thank you very much! I didn't realise that this function allocates a new string that needs to be freed :(
What about the rest? I think we fixed some bugs, but the aliases and error handling stuff are more like design issues. I have created a follow up if anyone wants to address this one day. As far as I'm concerned, this one is done.
comment:53 Changed 6 weeks ago by andrew_b
- Votes for changeset set to andrew_b
- Branch state changed from on review to approved
tests: vfs_path_string_convert - use UTF-8 to prevent creation of invalid converters
tests: path_manipulations / path_serialize - use UTF-8 to prevent creation of invalid converters
can be squashed.
comment:54 Changed 6 weeks ago by zaytsev
- Status changed from accepted to testing
- Votes for changeset changed from andrew_b to committed-master
- Resolution set to fixed
- Branch state changed from approved to merged
Merged as changeset:a24d45ffab3ee9f5e74f5b210f79e6ea91e3b69e . Wow!
comment:55 Changed 6 weeks ago by andrew_b
An aftershok.
if ! xgettext -h 2>&1 | grep -e '--keyword=' >/dev/null ; then
This line in autogen.sh is not quite correct. The help of program is translated and may not matched the pattern '--keyword='. Particularly, in Russian
$ xgettext -h 2>&1 | grep -e '--keyword=' $
and po-related files are not created. Because
$ xgettext -h 2>&1 | grep -e '--keyword' -k, --keyword[=СЛОВО] дополнительное ключевое слово для поиска -k, --keyword не использовать ключевые слова по умолчанию
comment:56 follow-up: ↓ 57 Changed 6 weeks ago by zaytsev
Oh, this is annoying, sorry.
What do you think is the best way to fix it? I wasn't happy about it anyway, because of course the text might go unnoticed, but I think the situation before, with random errors, was even worse. Do you have a better idea?
- grep -e '--keyword' without =
- LANG=C
- Print it in red using ANSI sequences?
- Print to stderr?
- Go to the beginning of the script and exit 1?
comment:57 in reply to: ↑ 56 Changed 6 weeks ago by andrew_b
LANG=C xgettext --help: output is in Russian.
LC_MESSAGES=C xgettext --help: output is in English
Changed 4 weeks ago by zaytsev
- Attachment 0001-buildsys-fix-bootstrapped-build-on-Solaris-and-syste.patch added
comment:58 Changed 4 weeks ago by zaytsev
Unfortunately, I managed to also break a bootstrapped build on Solaris. Ok to commit to master?
comment:59 Changed 4 weeks ago by andrew_b
Ok.
comment:60 Changed 4 weeks ago by zaytsev
Done, thanks!