
Ticket #3666 (reopened defect)
Improper use of IEC and SI prefixes for size in size_trunc()/size_trunc_len()
| Reported by: | michael-o | Owned by: | andrew_b |
|---|---|---|---|
| Priority: | major | Milestone: | Future Releases |
| Component: | mc-core | Version: | master |
| Keywords: | Cc: | egmont, zaytsev, mooffie, info@… | |
| Blocked By: | Blocking: | #3673, #3674, #3675, #3676 | |
| Branch state: | on hold | Votes for changeset: |
Description
This is a spinoff from https://github.com/MidnightCommander/mc/issues/109
Looking at lib/util.c, I see that virtually all SI prefixes are plain wrong. Additionally, man page talks about SI units, there aren't any. Only SI prefixes are incorrectly used. Bases arent 1024 and 1000, they are 2 and 10.
The best solution is to provide IEC prefixes (binary, KiB, MiB, GiB) and SI prefixes (decimal, kB, MB, GB), though file sizes (opposed to memory) are always calculated with base 10.
Patch is in preparation for this function and its callers.
Attachments
Change History
Changed 8 years ago by michael-o
- Attachment 0001-Ticket-3666-Improper-use-of-IEC-and-SI-prefixes-for-.patch added
comment:2 Changed 8 years ago by michael-o
Tested on:
FreeBSD bsd1home 10.3-RELEASE-p4 FreeBSD 10.3-RELEASE-p4 #0: Sat May 28 09:52:35 UTC 2016 root@amd64-builder.daemonology.net:/usr/obj/usr/src/sys/GENERIC i386
and
Linux ubuntu1ws 4.4.0-31-generic #50-Ubuntu SMP Wed Jul 13 00:07:12 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux DISTRIB_ID=Ubuntu DISTRIB_RELEASE=16.04 DISTRIB_CODENAME=xenial DISTRIB_DESCRIPTION="Ubuntu 16.04.1 LTS"
with these locales:
de_DE.UTF-8 en_US.UTF-8 ru_RU.UTF-8 es_ES.UTF-8
Unfortunately, I wasn't able to run autogen.sh on Ubuntu 14.04 LTS due to:
libtoolize: copying file `m4/ltversion.m4'
libtoolize: copying file `m4/lt~obsolete.m4'
configure.ac:324: error: possibly undefined macro: AC_MSG_WARN
If this token and others are legitimate, please use m4_pattern_allow.
See the Autoconf documentation.
autoreconf: /usr/bin/autoconf failed with exit status: 1
comment:3 follow-up: ↓ 4 Changed 8 years ago by egmont
Hi michael-o,
Could you please clarify what user facing changes this patch introduces, what user facing bugs it fixes? Also, how come that the "%s byte" and "%s bytes" strings disappear?
What will happen to the "Size" column, which is 7 characters by default? Is it the plan to use pedantic Ki, Mi whatever prefixes there, "wasting" 2 out of the 7 characters, leaving only 5 for the actual number (and hence reduce by a factor of 10 the boundaries before switching to a larger unit)?
Being sloppy rather than pedantic by not using the proper "Ki", "Mi" etc. is not nice, but perhaps justifiable by limited screen real estate. Not being consistent within mc is IMO much worse.
I'm not against modifying mc and making it more technically correct, I'd just like to make sure we're going to do it consistently, and understand and accept the downsides of the changes if any.
Thanks!
comment:4 in reply to: ↑ 3 ; follow-up: ↓ 12 Changed 8 years ago by michael-o
Hi egmont,
hopefully you have read the GitHub? issue first? I'd be happy to reply to you:
This is the first patch in a series of patches.
Replying to egmont:
Hi michael-o,
Could you please clarify what user facing changes this patch introduces, what user facing bugs it fixes? Also, how come that the "%s byte" and "%s bytes" strings disappear?
Currently, this patch fixes only the total size calculation for files and directories as well as the directory popup when it is being recursively traversed for size calculation (.e.g, /usr which is usally large).
"%s byte" and so forth has been removed because it is redundant now, properly scaled units are done in size_trunc() already, thus this msg id is not necessary. Additionally, a few translations even had duplicate words in it (German and others). (See the applied diff)
What will happen to the "Size" column, which is 7 characters by default? Is it the plan to use pedantic Ki, Mi whatever prefixes there, "wasting" 2 out of the 7 characters, leaving only 5 for the actual number (and hence reduce by a factor of 10 the boundaries before switching to a larger unit)?
Currently, nothing will happen to "size", "bsize" and alike. This is going to be addressed in a separate ticket. I did not want to introduce a huge change with a single ticket which cannot be easily reviewed. My plan is to fix size calculation which can properly scale between 0 and 9999 <scaled unit>, consuming at most 8 chars.
Being sloppy rather than pedantic by not using the proper "Ki", "Mi" etc. is not nice, but perhaps justifiable by limited screen real estate. Not being consistent within mc is IMO much worse.
I am aware of the limited size but accoring to the explanation above, size and bsize will only increase by 1 char if scaling will work as expected. Consisitently is key for me. As I already layed out. This is a separte ticket.
I'm not against modifying mc and making it more technically correct, I'd just like to make sure we're going to do it consistently, and understand and accept the downsides of the changes if any.
I fully agree and do not have an opposite opinion.
The first reason why I did not patch everything is because I do not waste time for a contribution where people might completely ignore or refuse to merge it. This has happened too often. As long as devs are at least willing to review and comment, I am happy to provide patches.
If you are uncertain, you can branch off master as 'size-display' (umbrella ticket necessary?), apply all of my patches there, see the result and merge it as a whole as soon as work has been completed.
Is that acceptable for you?
comment:5 follow-up: ↓ 6 Changed 8 years ago by andrew_b
- Owner set to andrew_b
- Status changed from new to accepted
- Branch state changed from no branch to on review
- Milestone changed from Future Releases to 4.8.18
Branch: 3666_iec_si_prefixes
Initial changeset:f5ac3e9e1b910c689727246738a4b5b714bd025e
Prefixes should be translatable. In the 2nd (temporary) commit of this branch I made that. All po updates are in the separate (last) commit.
comment:6 in reply to: ↑ 5 Changed 8 years ago by michael-o
Replying to andrew_b:
Branch: 3666_iec_si_prefixes
Initial changeset:f5ac3e9e1b910c689727246738a4b5b714bd025e
Prefixes should be translatable. In the 2nd (temporary) commit of this branch I made that. All po updates are in the separate (last) commit.
Great thank you. The translation is one of the ideas I already had in mind. I will check that because at least two languages do not use the term byte but octet (fr, ro). Reference, last paragraph.
I will continue with further changes.
Changed 8 years ago by michael-o
- Attachment 0001-Update-add-missing-translations-for-file-sizes-in-ar.patch added
comment:7 follow-up: ↓ 8 Changed 8 years ago by michael-o
Here is another patch for missing bits in Andrey's fixups. I have obstained to translate Bulgarian and Mongolian because I don't know wether they retain the Latin script or have Cyrillic terms. Other Cyrillic-based langs have been fixed, as well as octet (o) users.
comment:8 in reply to: ↑ 7 ; follow-up: ↓ 9 Changed 8 years ago by andrew_b
Replying to michael-o:
Here is another patch for missing bits in Andrey's fixups.
There is no need to fix *.po here. Translations are made via Transifex by native-speaking translators.
comment:10 in reply to: ↑ 9 ; follow-up: ↓ 11 Changed 8 years ago by andrew_b
Replying to michael-o:
Replying to andrew_b:
Replying to michael-o:
Here is another patch for missing bits in Andrey's fixups.
There is no need to fix *.po here. Translations are made via Transifex by native-speaking translators.
So we simply need to wait for them?
Yes.
Initially, we need an actual mc.pot in master. Then after some short time it will be automatically uploaded to transifex.com. Then *.po can be updated there.
comment:11 in reply to: ↑ 10 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to michael-o:
Replying to andrew_b:
Replying to michael-o:
Here is another patch for missing bits in Andrey's fixups.
There is no need to fix *.po here. Translations are made via Transifex by native-speaking translators.
So we simply need to wait for them?
Yes.
Initially, we need an actual mc.pot in master. Then after some short time it will be automatically uploaded to transifex.com. Then *.po can be updated there.
Fine, I can ignore my commit and will continue on the rest. Thanks for the clarification.
comment:12 in reply to: ↑ 4 ; follow-up: ↓ 13 Changed 8 years ago by egmont
- Cc egmont added
[summary of selected files] "%s byte" and so forth has been removed
Let's take a note about a UI change here: what used to be "12,345 bytes in 67 files" on the UI will from now on be "12,345 B in 67 files". Correct?
Especially if we save a few characters this way, could we write out the exact number if it fits? E.g. instead of "12,345,678 KiB" why not say e.g. "12,641,974,273 B"?
[individual files] Currently, nothing will happen to "size", "bsize" and alike. This is going to be addressed in a separate ticket. I did not want to introduce a huge change with a single ticket which cannot be easily reviewed. My plan is to fix size calculation which can properly scale between 0 and 9999 <scaled unit>, consuming at most 8 chars.
Since you said 9999 is the upper limit, I assume you're planning to properly continue it with a space and then the entire unit. E.g. what used to be "1234567" until now will from now on be "1234 kB" or "1205 KiB" (depending on the preferences), am I following you correctly?
How about small files, do you plan to add the " B" suffix there?
Until now, the first suffix appeared at the file size of around 10 megs (that is: "9999999" was displayed as-is, the next value became "9766K"). Except for this first change, all subsequent changes occurred around multiples of 1000 (or 1024), e.g. roughly at 1 gigabyte the display format changed from "K" to "M", and presumably roughly at 1 terabyte it changes from "M" to "G".
If you allow numbers up to 9999, you modify these boundaries to be roughly at 10 megs, 10 gigs etc. E.g. 9 megs would be something like "9000 KiB" whereas 11 megs would be "11 MiB". This I believe makes it much harder to subconsciously "feel" the file size magnitude by looking at it.
I'm wondering if maybe the right approach would be to allow numbers only up to 999 or 1023, showing a bit of decimal fraction digits. This way the suffix would directly give you the feeling about the file size's magnitude. E.g. instead of showing "1234567" or "1205 KiB", we could show "1.17 MiB". What do you think? (I'm not sure this would be the best, just wondering...)
I am aware of the limited size but accoring to the explanation above, size and bsize will only increase by 1 char if scaling will work as expected. Consisitently is key for me. As I already layed out. This is a separte ticket.
Increase by 1 char, resulting in the filename shrinking from 16 to 15 chars at the default terminal width of 80 columns; and you still lose two digits of information. In turn, a lot of screen real estate would be wasted for those spaces as well as "i" and "B" letters.
Yup, overall, if I understand your proposal correctly, we'll lose 3 character columns per panel. One for an aestethical space, one for a pedantic "i", and one for that "B" carrying no information whatsoever. I'm not happy, even though I'm not sure what would be a better solution. At least I'd like to have some discussion/brainstorming about it.
For starter, how about leaving everything as-is now, except for fixing the upper/lowercase k/m/g letters (if they're broken at all), and adding an "i" to the header if IEC is selected? This one also obviously has downsides (around the translation of that "Size(i)" label) but let's see if this idea can be continued...
By the way, note how much my proposal in ticket #3087 got frowned upon...
comment:13 in reply to: ↑ 12 ; follow-up: ↓ 14 Changed 8 years ago by michael-o
Replying to egmont:
[summary of selected files] "%s byte" and so forth has been removed
Let's take a note about a UI change here: what used to be "12,345 bytes in 67 files" on the UI will from now on be "12,345 B in 67 files". Correct?
Correct. I do also plan to create a ticket which drops the comma two simple reasons: it is not locale aware and completely confuses people which do not use en_* locales like I do here in German or Russian (which I am a native).
Especially if we save a few characters this way, could we write out the exact number if it fits? E.g. instead of "12,345,678 KiB" why not say e.g. "12,641,974,273 B"?
Of course we could, the people do not want to see huge numbers, since humans are bad in reading a lot of digits. Its like reading an IBAN with several consecutive zeroes.
[individual files] Currently, nothing will happen to "size", "bsize" and alike. This is going to be addressed in a separate ticket. I did not want to introduce a huge change with a single ticket which cannot be easily reviewed. My plan is to fix size calculation which can properly scale between 0 and 9999 <scaled unit>, consuming at most 8 chars.
Since you said 9999 is the upper limit, I assume you're planning to properly continue it with a space and then the entire unit. E.g. what used to be "1234567" until now will from now on be "1234 kB" or "1205 KiB" (depending on the preferences), am I following you correctly?
Almost, yes. In the first place, I do not want to fiddle with the scaling logic as in size_trunc_len(). This is too much change in one patch. The logic mostly relies on the len input limited by the buffer which produces for the same size different outputs in different spots, like size column or info panel. This confuses me too.
How about small files, do you plan to add the " B" suffix there?
Yes, it clearly denotes the unit. Suffixes w/o units aren't valid as per definition.
Until now, the first suffix appeared at the file size of around 10 megs (that is: "9999999" was displayed as-is, the next value became "9766K"). Except for this first change, all subsequent changes occurred around multiples of 1000 (or 1024), e.g. roughly at 1 gigabyte the display format changed from "K" to "M", and presumably roughly at 1 terabyte it changes from "M" to "G".
If you allow numbers up to 9999, you modify these boundaries to be roughly at 10 megs, 10 gigs etc. E.g. 9 megs would be something like "9000 KiB" whereas 11 megs would be "11 MiB". This I believe makes it much harder to subconsciously "feel" the file size magnitude by looking at it.
I'm wondering if maybe the right approach would be to allow numbers only up to 999 or 1023, showing a bit of decimal fraction digits. This way the suffix would directly give you the feeling about the file size's magnitude. E.g. instead of showing "1234567" or "1205 KiB", we could show "1.17 MiB". What do you think? (I'm not sure this would be the best, just wondering...)
Personally, I completely agree with you. I do dislike the scaling logic which is implemented right now because it scales way too late and shows huge numbers like 120345 kB. This is impossible to read. But as I have said before, I want to fix the units first and then take care of the scaling logic. Though, I won't change it without your consent.
I have applied a similar approach a couple of months ago to a formatter written for Apache Maven, displaying file sizes and download speed. See nested class FileSizeFormat along with test cases.
The basic idea is to have one decimal position (with seperator from LC_NUMERIC) for sizes between 0 and 10 and whole numbers above 10. Automatically scale between 1 and 1000. It is space efficient, consize and easy to read. You never exceed 8 chars.
I am aware of the limited size but accoring to the explanation above, size and bsize will only increase by 1 char if scaling will work as expected. Consisitently is key for me. As I already layed out. This is a separte ticket.
Increase by 1 char, resulting in the filename shrinking from 16 to 15 chars at the default terminal width of 80 columns; and you still lose two digits of information. In turn, a lot of screen real estate would be wasted for those spaces as well as "i" and "B" letters.
That is correct. A sacrifice for technical correctness. Consider that proper GUIs/operating systems do use only SI prefixes for storage sizes, Gnome, OS X, etc. Microsoft is too stupid for that. Ultimately, people do not really understand why 1 GB is not 1 000 000 000 B.
Yup, overall, if I understand your proposal correctly, we'll lose 3 character columns per panel. One for an aestethical space, one for a pedantic "i", and one for that "B" carrying no information whatsoever. I'm not happy, even though I'm not sure what would be a better solution. At least I'd like to have some discussion/brainstorming about it.
In the first place, you will lose 3 chars but add proper, unambigious information. There is no 'aestethical space' because this is always mandatory between number and unit. "B" IS the unit. k, M, G aren't units. In fact, K is Kelvin. This is even more confusing.
You would lose at most 1 char, if you would apply a better scaling logic which I have proposed a few paragraphs above.
I am perfectly fine with a discussion where we can retain space efficiency and proper readability.
For starter, how about leaving everything as-is now, except for fixing the upper/lowercase k/m/g letters (if they're broken at all), and adding an "i" to the header if IEC is selected? This one also obviously has downsides (around the translation of that "Size(i)" label) but let's see if this idea can be continued...
From my point of view, size_trunc() and size_trunc_len() can be collapsed into one method with less logic and code. Especially size_trunc_len() performs operations for two different concerns which it shouldn't. During my review, I found several other spots where no/fixed scale is applied and only base 2 is used, regardless of the settings.
By the way, note how much my proposal in ticket #3087 got frowned upon...
I read the entire conversation and it was quite daunting. I follow your point and if I check the shortcuts with my German keyboard, I have absolute no idea what M-h means and how I can even enter some of them because the key combination is impossible without a n-rollover keyboard.
comment:14 in reply to: ↑ 13 ; follow-up: ↓ 15 Changed 8 years ago by egmont
Replying to michael-o:
[long format]
I do also plan to create a ticket which drops the comma two simple reasons: it is not locale aware and completely confuses people which do not use en_* locales like I do here in German or Russian (which I am a native).
Of course we could, the people do not want to see huge numbers, since humans are bad in reading a lot of digits. Its like reading an IBAN with several consecutive zeroes.
These two seem to contradict each other. I agree that reading a large unstructured number is very hard. So why make it even harder by dropping the separator? I guess it should be fixed instead: make the thousands-separator locale-dependent.
An unstructured number has IMO two advantages over the one with thousands separators: easy copy-pasting (let's say to "bc"), as well as iTerm 3 beta and gnome-terminal 3.20 showing useful information about the number on right click (gnome-terminal ticket with screenshot: https://bugzilla.gnome.org/show_bug.cgi?id=741728). Despite these two, I'd rather go for mc structuring these numbers properly though.
Another idea to explore might be to use different color/boldness/underlying for every 3 characters, e.g. "1234567890 bytes" or some other visual differentiation.
Or, similarly to the gnome-terminal feature, mc could always show the entire number as well as a Ki / Mi / Gi converted value, e.g. "1234567890 (~1.14 GiB)". (Is there enough room for this? Probably not always.)
[short format]
That is correct. A sacrifice for technical correctness. Consider that proper GUIs/operating systems do use only SI prefixes for storage sizes, Gnome, OS X, etc. Microsoft is too stupid for that. Ultimately, people do not really understand why 1 GB is not 1 000 000 000 B.
I have a strong guts feeling that changing the current format to having those " B", " KiB" etc. suffixes and in turn much shorter room for the actual number will be something that many people will strongly dislike, and would prefer to revert to the old display format (which is technically less correct, but shows more information on the available limited space).
At the very least I strongly recommend that whatever you'll be doing with the Size field should have a config option (or a new field type in User-defined Listing mode) to revert to the old behavior. I'd also be happy to hear others' opinion here :)
comment:15 in reply to: ↑ 14 ; follow-up: ↓ 16 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
An unstructured number has IMO two advantages over the one with thousands separators: easy copy-pasting (let's say to "bc"), as well as iTerm 3 beta and gnome-terminal 3.20 showing useful information about the number on right click (gnome-terminal ticket with screenshot: https://bugzilla.gnome.org/show_bug.cgi?id=741728). Despite these two, I'd rather go for mc structuring these numbers properly though.
I agree with copy and paste. This is indeed an issue. Regarding your Gnome issue, GNU ls supports 'ls --si' and you are done. Your screenshot has prefixes only and misses the unit.
Another idea to explore might be to use different color/boldness/underlying for every 3 characters, e.g. "1234567890 bytes" or some other visual differentiation.
Or, similarly to the gnome-terminal feature, mc could always show the entire number as well as a Ki / Mi / Gi converted value, e.g. "1234567890 (~1.14 GiB)". (Is there enough room for this? Probably not always.)
I would show the full byte size as well as the scaled one in the info/detail panel only.
[short format]
That is correct. A sacrifice for technical correctness. Consider that proper GUIs/operating systems do use only SI prefixes for storage sizes, Gnome, OS X, etc. Microsoft is too stupid for that. Ultimately, people do not really understand why 1 GB is not 1 000 000 000 B.
I have a strong guts feeling that changing the current format to having those " B", " KiB" etc. suffixes and in turn much shorter room for the actual number will be something that many people will strongly dislike, and would prefer to revert to the old display format (which is technically less correct, but shows more information on the available limited space).
At the very least I strongly recommend that whatever you'll be doing with the Size field should have a config option (or a new field type in User-defined Listing mode) to revert to the old behavior. I'd also be happy to hear others' opinion here :)
An option is always possible and I am not rejecting it. We should though by default use the proper format and have a fallback option.
I have attached a patch (scaling.patch) for scaling for size_trunc(). Apply locally and look how it works. It makes magnitudes instantly visible. This is actually what I would ultimately propose.
comment:16 in reply to: ↑ 15 Changed 8 years ago by egmont
Replying to michael-o:
Regarding your Gnome issue, GNU ls supports 'ls --si' and you are done. Your screenshot has prefixes only and misses the unit.
That screenshot is just one example, the point was to make it work with any command, not just ls. Unit is missing because gnome-terminal cannot possibly know what the unit of the number is, it only recognizes the number itself (it would be incorrect to assume bytes).
Note, however, how 'ls --si' also happily omits the space and the letters "i" and "B" to save space, even though (unlike mc) it has as much space as it wants to (it can wrap a file's entry into the next terminal row, no problem). I guess I'd rather see mc taking this direction too, rather than being fully pedantic.
Changed 8 years ago by michael-o
- Attachment 0001-.po-Removed-redundant-words-from-msgid-s-in-d-file-t.patch added
comment:17 Changed 8 years ago by michael-o
Egmont, I have created two more patches (0001-size_trunc-autoscale-size-with-proper-prefixes.patch and 0002-size_trunc_len-drastically-simplify-function-by-appl.patch) which autoscale the size up to gigabytes/gibibytes (TB and TiB can be added later). All static buffer which are too small have been increased. You only need at most 9 chars including NULL. Note that for non-Latin languges more than 9 bytes are necessary (UTF-8 multibyte). This has been added to the small buffers as well as for the size and bsize columns. I cannot tell about the big ones whether they might overflow or not. From my testing, it does not. This is before the patch:
./src/filemanager/chown.c:371 => B, buffer[60], chown_cmd() ./src/filemanager/filegui.c:554 => B, buffer[128], overwrite_query_dialog() ./src/filemanager/filegui.c:559 => B, buffer[128], overwrite_query_dialog() ./src/filemanager/filegui.c:1016 => B, buffer[5], file_progress_show_total() ./src/filemanager/filegui.c:1021 => B, buffer[5], file_progress_show_total() ./src/filemanager/info.c:181 => kB, buffer[5] ./src/filemanager/info.c:182 => kB, buffer[5] ./src/filemanager/info.c:236 => B, buffer[9] ./src/filemanager/panel.c:518 => B, string_file_size() => size/bsize: 7 ./src/filemanager/panel.c:1159 => kB, buffer[5], show_free_space() ./src/filemanager/panel.c:1161 => kB buffer[5], show_free_space()
"size"/"bsize" grow by one char only.
What is left:
- Transfer speeds could use it too:
src/filemanager/filegui.c:371: if (bps > 1024 * 1024) src/filemanager/filegui.c:373: g_snprintf (buffer, BUF_TINY, _("%.2f MB/s"), bps / (1024 * 1024.0)); src/filemanager/filegui.c:375: else if (bps > 1024) src/filemanager/filegui.c:377: g_snprintf (buffer, BUF_TINY, _("%.2f KB/s"), bps / 1024.0); src/filemanager/filegui.c:897: gauge_set_value (ui->progress_file_gauge, 1024, (int) (1024 * done / total)); src/filemanager/filegui.c:970: gauge_set_value (ui->progress_total_gauge, 1024, src/filemanager/filegui.c:971: (int) (1024 * copied_bytes / ctx->progress_bytes));
- Documentation needs to be aligned
- The Panel Option would ideally renamed to File size prefixes: [IEC], [SI] (dropdown) The config file and code would remain as-is for maximum compat, though they are confusing
If you intend to have the "classic" style, we could probably add this option:
File size style: [classic], [modern]
Serialzed to: file_size_style=classic or modern (classic defaults)
Consider that buffers would still need to retain as big as necessary for "modern" style unless you have a better idea how to accomondate both.
WDYT?
comment:18 Changed 8 years ago by michael-o
- Summary changed from Improper use of IEC and SI prefixes for size in size_trunc() to Improper use of IEC and SI prefixes for size in size_trunc()/size_trunc_len()
Changed 8 years ago by michael-o
- Attachment 0001-size_trunc-autoscale-size-with-proper-prefixes.patch added
Changed 8 years ago by michael-o
- Attachment 0002-size_trunc_len-drastically-simplify-function-by-appl.patch added
comment:19 follow-up: ↓ 20 Changed 8 years ago by andrew_b
0001-size_trunc-autoscale-size-with-proper-prefixes.patch: I think we shouldn't lose the high precision in display_total_marked_size(). This is single place where such precision is shown unlike other places where scaling is applied.
comment:20 in reply to: ↑ 19 ; follow-up: ↓ 21 Changed 8 years ago by michael-o
Replying to andrew_b:
0001-size_trunc-autoscale-size-with-proper-prefixes.patch: I think we shouldn't lose the high precision in display_total_marked_size(). This is single place where such precision is shown unlike other places where scaling is applied.
Interesting point, though I do not understand why. The accumulated byte value can get really large with 9, 10 or more places, barely readable. I would expect to see the raw value *and* the scaled value in the info panel: 102 MB (102124456999 B, 199461830 blocks).
Can you explain why the precision is necessary in the total marked size?
comment:21 in reply to: ↑ 20 Changed 8 years ago by andrew_b
Replying to michael-o:
Can you explain why the precision is necessary in the total marked size?
And why not? We already have it for many years. Why we should lose it?
Info panel is not a subject in this case. It doesn't show summary size of marked files.
comment:22 follow-up: ↓ 23 Changed 8 years ago by egmont
I second andrew_b's opinion here. There might be use cases we don't even think of. Doing arithmetics with that number outside of mc, using as a basic "checksum" to check whether the size is what's expected, etc... There's room to show that information, so let's do it. The info panel is IMO cumbersome to get to.
comment:23 in reply to: ↑ 22 ; follow-up: ↓ 24 Changed 8 years ago by michael-o
Replying to egmont:
I second andrew_b's opinion here. There might be use cases we don't even think of. Doing arithmetics with that number outside of mc, using as a basic "checksum" to check whether the size is what's expected, etc... There's room to show that information, so let's do it. The info panel is IMO cumbersome to get to.
I see. So you would prefer to see "xxx MB (yyy B) in n directories"?
comment:24 in reply to: ↑ 23 ; follow-up: ↓ 25 Changed 8 years ago by egmont
Replying to michael-o:
I see. So you would prefer to see "xxx MB (yyy B) in n directories"?
Yup, maybe like "1234567 B (1.17 MiB) in 1234 files"?
(Note: I'd swap what's outside and inside the parantheses compared to your suggestion.)
Whenever it becomes too long (wouldn't fit the available width) we could fallback to a more concise notation, e.g. "123456789012 B (107.3 GiB) / 1234 files" (omitting the "in" would probably save more in other languages), or even simply "123456789012 B (107.3 GiB) / 1234", or stop showing either the exact overall size or the approximation.
How does it look to you?
A bit of my worry is that with IEC it looks okay, with SI it's unnecessarily repeating "1234567 B (1.23 MB)". Not sure what to do here. Maybe here we could omit the apprimated value if we have thousands separators and just simply show "1,234,567 B in 1234 files" (wait, this is what we do currently).
comment:25 in reply to: ↑ 24 ; follow-up: ↓ 26 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
I see. So you would prefer to see "xxx MB (yyy B) in n directories"?
Yup, maybe like "1234567 B (1.17 MiB) in 1234 files"?
(Note: I'd swap what's outside and inside the parantheses compared to your suggestion.)
Yes, this is just swapped. The question is which people like to see first? Most UIs display scaled unit first and then the raw value. If the raw value is getting too large this won't be helpful.
Whenever it becomes too long (wouldn't fit the available width) we could fallback to a more concise notation, e.g. "123456789012 B (107.3 GiB) / 1234 files" (omitting the "in" would probably save more in other languages), or even simply "123456789012 B (107.3 GiB) / 1234", or stop showing either the exact overall size or the approximation.
How does it look to you?
I am not really fond of this. This gets too complex, and unreadable by leaving more and more information out. Additionally, you have to constantly calculate whether your localized strings fits into the panel and reapply and print again. I would leave it fully written because it will always behave the same way. there are probably 30 chars available, I consider that terabytes will fit it.
A bit of my worry is that with IEC it looks okay, with SI it's unnecessarily repeating "1234567 B (1.23 MB)". Not sure what to do here. Maybe here we could omit the apprimated value if we have thousands separators and just simply show "1,234,567 B in 1234 files" (wait, this is what we do currently).
I wouldn't neither worry about repetition because the UI is consistent after all. People see exact information. Leave as-is with bytes only yields to huge unreadble numbers, not copiable as you have written earlier.
We can do the following: provide a new option "[] Scale marked total size". If selected, people see scaled size, if not they see the raw byte value as with %ju. Easy and understandable. If you want to make it even better, provide a selection option: "Marked total size style: [raw, scaled, both]" which maps to an enum. Default would be deselected or raw.
This should satisfy all needs. If you prefer to see raw values, you get them. I prefer to see scaled ones.
comment:26 in reply to: ↑ 25 ; follow-up: ↓ 27 Changed 8 years ago by egmont
Replying to michael-o:
Yes, this is just swapped. The question is which people like to see first? Most UIs display scaled unit first and then the raw value. If the raw value is getting too large this won't be helpful.
Could you please provide references (e.g. screenshots) to that "most UIs"?
I believe that parentheses (in this case) "explain" the aforementioned value, in which sense it makes sense to convert from bytes to MB, GB, but does not make sense the other way around, as there's no way to derive the exact number from the MB, GB approximation.
But I don't have references to defend this, so if you prove that your suggestion is a common UI approach then I'm fine.
We can do the following: provide a new option "[] Scale marked total size". If selected, people see scaled size, if not they see the raw byte value as with %ju. Easy and understandable. If you want to make it even better, provide a selection option: "Marked total size style: [raw, scaled, both]" which maps to an enum. Default would be deselected or raw.
This should satisfy all needs. If you prefer to see raw values, you get them. I prefer to see scaled ones.
You assume that one's need is to either always see the exact value, or to always see the approximated one. At least for me this is not the case.
I often wish to see the exact value, and often the approximated one that suggests the magnitude. And I'd prefer to "switch" just by looking at the screen (that is, seeing both there) rather than by going to whichever menu entry or remembering a long hotkey sequence to toggle.
With the current behavior I get both (albeit not a copy-pasteable number). With the new behavior I'd only get one at a time. I'd either need to toggle mc's setting, or use iterm's/gnome-terminal's right-click menu that shows the detailed information. The latter one is probably more convenient out of these two, but not available to most of our users. A definite advantage is copy-pasteability.
I guess I could easily get used to the new behavior, but I'm heavily in doubt whether our users will see this as an improvement.
comment:27 in reply to: ↑ 26 ; follow-up: ↓ 28 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
Yes, this is just swapped. The question is which people like to see first? Most UIs display scaled unit first and then the raw value. If the raw value is getting too large this won't be helpful.
Could you please provide references (e.g. screenshots) to that "most UIs"?
I believe that parentheses (in this case) "explain" the aforementioned value, in which sense it makes sense to convert from bytes to MB, GB, but does not make sense the other way around, as there's no way to derive the exact number from the MB, GB approximation.
Your reasoning is correct here. You can't derive but people won't do it anyway as long as you provide the raw value.
But I don't have references to defend this, so if you prove that your suggestion is a common UI approach then I'm fine.
I did some digging with Google and my VMs (this applies to file details, I assume it applies to marked files in a detailed view too):
OS X: https://i1.wp.com/www.macissues.com/wp-content/uploads/2014/05/FinderInfoMetaData.png
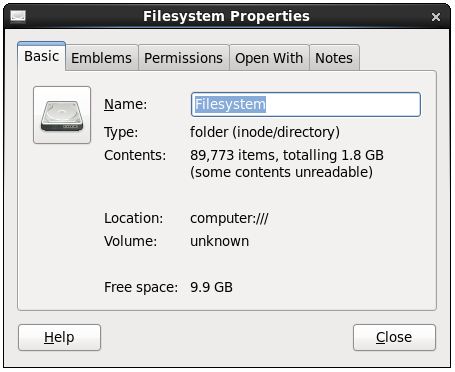
Gnome on RHEL6: http://www.techotopia.com/images/1/14/Rhel6_filesystem_properties.jpg
Dolphin on KDE: http://pclosmag.com/html/issues/201003/images/dolphin-14.png
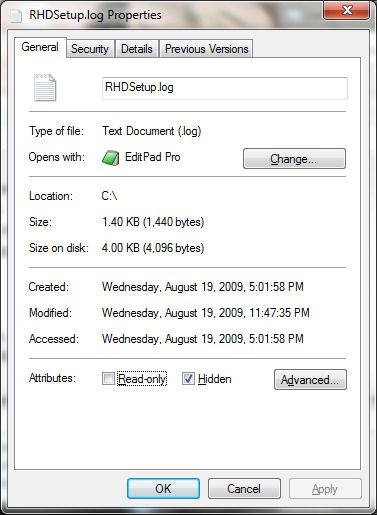
Windows 7: http://www.nicholasoverstreet.com/wp-content/uploads/2010/03/timestampgood.jpg
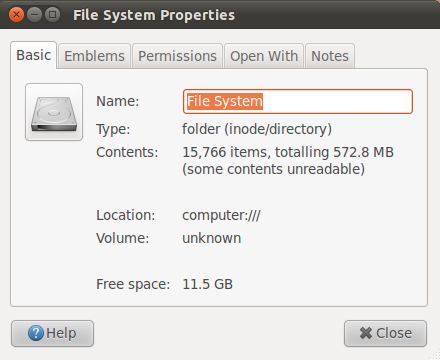
Ubuntu w/ Unity: http://www.techotopia.com/images/5/53/Ubuntu_11_unity_file_system_properties.jpg
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I mostly see scaled only or scaled with raw value in parentheses.
We can do the following: provide a new option "[] Scale marked total size". If selected, people see scaled size, if not they see the raw byte value as with %ju. Easy and understandable. If you want to make it even better, provide a selection option: "Marked total size style: [raw, scaled, both]" which maps to an enum. Default would be deselected or raw.
This should satisfy all needs. If you prefer to see raw values, you get them. I prefer to see scaled ones.
You assume that one's need is to either always see the exact value, or to always see the approximated one. At least for me this is not the case.
I often wish to see the exact value, and often the approximated one that suggests the magnitude. And I'd prefer to "switch" just by looking at the screen (that is, seeing both there) rather than by going to whichever menu entry or remembering a long hotkey sequence to toggle.
With the current behavior I get both (albeit not a copy-pasteable number). With the new behavior I'd only get one at a time. I'd either need to toggle mc's setting, or use iterm's/gnome-terminal's right-click menu that shows the detailed information. The latter one is probably more convenient out of these two, but not available to most of our users. A definite advantage is copy-pasteability.
I have offered three options actually. You can have both in one view. It is simply not true that you can have both currently, you get a partially scaled value, neither fully nor raw. I do not consider it usable/readable at all. Looking at my Mediatomb library, I see tens of millions of kilobytes. Not really helpful.
I guess I could easily get used to the new behavior, but I'm heavily in doubt whether our users will see this as an improvement.
Great. Anything you dislike leaving people the choice to have three options with having seeing both as default?
comment:28 in reply to: ↑ 27 ; follow-up: ↓ 29 Changed 8 years ago by egmont
Replying to michael-o:
I mostly see scaled only or scaled with raw value in parentheses.
Okay, then. Thanks.
I have offered three options actually. You can have both in one view. It is simply not true that you can have both currently, you get a partially scaled value, neither fully nor raw. I do not consider it usable/readable at all. Looking at my Mediatomb library, I see tens of millions of kilobytes. Not really helpful.
Up to the value of "999,999,999" you get it spelled out exactly, and the grouping of 3 lets you immediately see that this is approx. 999 megabytes. Continuing this pattern for even larger numbers would IMO provide a quite good solution (despite its known downsides e.g. unability to copy-paste), it would show the exact number as well as the magnitude at the same time.
What I personally never really cared about is the difference between IEC and SI - exactly what you're trying to pedantically address in this bug. Is it 1 GiB or 1 GB or 1.07 GB? It hardly ever makes a difference in real life.
I'm sorry but I'm totally lost: could you please provide examples of how the different modes you'd offer would look like for different magnitudes?
comment:29 in reply to: ↑ 28 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
I mostly see scaled only or scaled with raw value in parentheses.
Okay, then. Thanks.
I have offered three options actually. You can have both in one view. It is simply not true that you can have both currently, you get a partially scaled value, neither fully nor raw. I do not consider it usable/readable at all. Looking at my Mediatomb library, I see tens of millions of kilobytes. Not really helpful.
Up to the value of "999,999,999" you get it spelled out exactly, and the grouping of 3 lets you immediately see that this is approx. 999 megabytes. Continuing this pattern for even larger numbers would IMO provide a quite good solution (despite its known downsides e.g. unability to copy-paste), it would show the exact number as well as the magnitude at the same time.
Exactly, why do I need to scale myself if the machine can do that for me? I am not really interested wether is 100 kB larger or not.
What I personally never really cared about is the difference between IEC and SI - exactly what you're trying to pedantically address in this bug. Is it 1 GiB or 1 GB or 1.07 GB? It hardly ever makes a difference in real life.
The difference is how the values are displayed and the unit does not really show what base is applied. With a proper patch, you immediately see the base 2 or 10. Not exactly the difference itself.
I'm sorry but I'm totally lost: could you please provide examples of how the different modes you'd offer would look like for different magnitudes?
Yes, sure.
Mode 'raw':
100000 B in 10 files
560000000000 B in 1001 files
Mode 'scaled':
SI (base 10):
100 B in 10 files
100 kB in 100 files
950 MB in 200 files
560 GB in 1001 files
IEC (base 2):
100 B in 10 files
98 KiB in 100 files
940 MiB in 200 files
1020 MiB in 220 files
550 GiB in 1001 files
Mode 'both':
SI (base 10):
100 B in 10 files
100 kB (100000 B) in 100 files
950 MB (950201123 B) in 200 files
560 GB (560100245124 B) in 1001 files
IEC (base 2):
100 B in 10 files
98 KiB (100400 B) in 100 files
940 MiB (985661900 B) in 200 files
1020 MiB (1069547520 B) in 220 files
550 GiB (590558003200 B) in 1001 files
Note that in 'both' mode with a value below 1000 bytes or 1024 bytes, 'raw' mode is applied to avoid duplicate information.
comment:30 follow-up: ↓ 31 Changed 8 years ago by egmont
Thanks a lot! It's really nice to see it like this.
I like it pretty much, my only concern is that the "both" mode can easily overflow (that is, not fit in the given room) at 80 columns, let alone in other languages where "in" and "files" are longer words. This is something I'd like to see getting addressed.
Here are some ideas, I'm curious about your preference:
- Stop displaying either the raw or the scaled number if the entire string doesn't fit.
- Let it overflow to the other panel (whichever has the focus should "win"). (Ugly and not sure how easily implementable, but useful.)
- Shorten by omitting the words "in" and "files", just use e.g. a "/" as separator, and/or omitting spaces before the units.
- Continue two lines below in the left (to the left of the disk usage information).
- (Any other idea?)
The latter one suggests we also have to figure out what to display if the mini status is disabled for the panel. (This is something that just occurred to me, I've never used mc in this mode.) Currently the number of files is omitted.
comment:31 in reply to: ↑ 30 ; follow-up: ↓ 32 Changed 8 years ago by michael-o
Replying to egmont:
Thanks a lot! It's really nice to see it like this.
I like it pretty much, my only concern is that the "both" mode can easily overflow (that is, not fit in the given room) at 80 columns, let alone in other languages where "in" and "files" are longer words. This is something I'd like to see getting addressed.
I have thought of this too but there is no silver bullet. We have at most 38 chars in default mode/size because we have two panes for the marked total size.
Here are some ideas, I'm curious about your preference:
- Stop displaying either the raw or the scaled number if the entire string doesn't fit.
This would mean to constantly check and recalculate. Adding additional complexity. Not really favorable.
- Let it overflow to the other panel (whichever has the focus should "win"). (Ugly and not sure how easily implementable, but useful.)
Have you actually tried this? In my opinion, this won't actually happen. I have tried this and resized my PuTTY window to the smallest possible size. mc is smart enough to detect that. It has automatically shortened the string in the center with a tilde (~). No overflow has occured.
- Shorten by omitting the words "in" and "files", just use e.g. a "/" as separator, and/or omitting spaces before the units.
I wouldn't do this for two reasons: (1) changes wouldn't look harmonic anymore and people might consider it as a bug when words start to disappear. Moreover, if you mark large directories/files in the first place, you won't see the word "files" at all and will ask yourself: What does this output mean? "100 GB / 1000".
- Continue two lines below in the left (to the left of the disk usage information).
Is this actually possible? My knowledge of ncurses in non-existent.
- (Any other idea?)
The latter one suggests we also have to figure out what to display if the mini status is disabled for the panel. (This is something that just occurred to me, I've never used mc in this mode.) Currently the number of files is omitted.
From my findings, an overflow won't happen but a shorting like "├─ 5,3 MB ~ateien ─┤".
I have patched locally to "%s (%ju B) in %d file", "%s (%ju B) in %d files" and I see this in a small SSH sesssion:
Left File Command Options Right ┌<─ /mediatomb ─────────────────────────────.[^]>┐┌<─ ~/Projekte/mc │.n Name │ Size │ Modify time ││.n Name │/.. │ UP--DIR│ 2016-08-11 20:41││/.. │/H.264 │ 170 MB│ 2016-07-24 21:17││/autom4te.cache │/ext │ 0 B│ 2016-07-24 22:04││/config │ Eliane Lim~a BBB.mp4│ 18 MB│ 2016-07-31 14:24││/contrib │ GiselleSec~R.com.mp4│ 483 MB│ 2016-07-31 13:36││/doc │ Salao Moda~ipsbr.mp4│ 503 MB│ 2016-07-31 16:34││/intl │ TudoPelaAu~ipsBR.mp4│ 289 MB│ 2016-07-31 14:40││/lib │ bigfile │ 1.1 GB│ 2016-07-30 16:40││/m4 │ bigfile.1 │ 248 B│ 2016-07-30 16:41││/m4.include │ bigfile.bin │ 1.1 GB│ 2016-07-30 16:41││/maint │ d.mkv │ 189 MB│ 2016-07-24 20:06││/misc │ rabbi-jacob.mp4 │ 506 MB│2013-12-09 18:42 ││/po │ │ │ ││/src │ │ │ ││/tests │ │ │ ││ 0001-.po-R~le-t │ │ │ ││ 0001-size_~ixes │ │ │ ││ 0002-size_~appl │ │ │ ││ ABOUT-NLS │ │ │ ││ AUTHORS │ │ │ ││@COPYING │ │ │ ││ ChangeLog │ │ │ ││@INSTALL │ │ │ ││ Makefile ├────── 4.3 GB (4302077093 B) in 11 files ───────┤├──────────────── │ rabbi-jacob.mp4 ││UP--DIR └────────────────────────── 158 GB/187 GB (84%) ─┘└──────────────── [mosipov@bsd1home /mediatomb]$ Left File Command Options Right ┌<─ /mediatomb ────────────────.[^]>┐┌<─ ~/Projekte/mc ──────────── │.n Name │ Size │ Modify time ││.n Name │ Size │ Modify │/.. │P--DIR│2016-08-11 20:41││/.. │UP--DIR│2016-08-1 │/H.264 │170 MB│2016-07-24 21:17││/autom~ache│ 512 B│2016-07-2 │/ext │ 0 B│2016-07-24 22:04││/config │ 512 B│2016-07-2 │ Elian~.mp4│ 18 MB│2016-07-31 14:24││/contrib │ 512 B│2016-08-1 │ Gisel~.mp4│483 MB│2016-07-31 13:36││/doc │ 512 B│2016-08-1 │ Salao~.mp4│503 MB│2016-07-31 16:34││/intl │ 1.5 kB│2016-08-1 │ TudoP~.mp4│289 MB│2016-07-31 14:40││/lib │ 1.5 kB│2016-08-1 │ bigfile │1.1 GB│2016-07-30 16:40││/m4 │ 1.0 kB│2016-07-2 │ bigfile.1 │ 248 B│2016-07-30 16:41││/m4.include│ 1.0 kB│2016-07-2 │ bigfi~.bin│1.1 GB│2016-07-30 16:41││/maint │ 512 B│2016-07-2 │ d.mkv │189 MB│2016-07-24 20:06││/misc │ 512 B│2016-08-1 │ rabbi~.mp4│506 MB│013-12-09 18:42 ││/po │ 2.6 kB│2016-08-1 │ │ │ ││/src │ 1.5 kB│2016-08-1 │ │ │ ││/tests │ 512 B│2016-08-1 │ │ │ ││ 0001-~atch│ 2.4 kB│2016-07-3 │ │ │ ││ 0001-~atch│ 4.3 kB│2016-07-3 ├─ 4.3 GB (4302077~ B) in 11 files ─┤├───────────────────────────── │ rabbi-jacob.mp4 ││UP--DIR └───────────── 158 GB/187 GB (84%) ─┘└────────────── 158 GB/187 GB [mosipov@bsd1home /mediatomb]$ Left File Command Options Right ┌<─ /mediatomb ───────────────.[^]>┐┌<─ ~/Projekte/mc ───────────── │.n Name │ Size │ Modify time ││.n Name │ Size │ Modify ti │/.. │P--DIR│016-08-11 20:41││/.. │P--DIR│2016-08-10 │/H.264 │170 MB│016-07-24 21:17││/autom~ache│ 512 B│2016-07-27 │/ext │ 0 B│016-07-24 22:04││/config │ 512 B│2016-07-27 │ Elian~.mp4│ 18 MB│016-07-31 14:24││/contrib │ 512 B│2016-08-11 │ Gisel~.mp4│483 MB│016-07-31 13:36││/doc │ 512 B│2016-08-11 │ Salao~.mp4│503 MB│016-07-31 16:34││/intl │1.5 kB│2016-08-11 │ TudoP~.mp4│289 MB│016-07-31 14:40││/lib │1.5 kB│2016-08-11 │ bigfile │1.1 GB│016-07-30 16:40││/m4 │1.0 kB│2016-07-27 │ bigfile.1 │ 248 B│016-07-30 16:41││/m4.include│1.0 kB│2016-07-25 │ bigfi~.bin│1.1 GB│016-07-30 16:41││/maint │ 512 B│2016-07-25 │ d.mkv │189 MB│016-07-24 20:06││/misc │ 512 B│2016-08-11 │ rabbi~.mp4│506 MB│13-12-09 18:42 ││/po │2.6 kB│2016-08-11 │ │ │ ││/src │1.5 kB│2016-08-11 │ │ │ ││/tests │ 512 B│2016-08-11 │ │ │ ││ 0001-~atch│2.4 kB│2016-07-31 ├─ 4.3 GB (4302077~B) in 11 files ─┤├────────────────────────────── │ rabbi-jacob.mp4 ││UP--DIR └──────────── 158 GB/187 GB (84%) ─┘└───────────── 158 GB/187 GB (8 [mosipov@bsd1home /mediatomb]$ Left File Command Options Right ┌<─ /mediatomb ────────────.[^]>┐┌<─ ~/Projekte/mc ──────────.[^]>┐ │.n Name │Size │ Modify time ││.n Name │Size │ Modify time │ │/.. │--DIR│16-08-11 20:41││/.. │--DIR│016-08-10 17:16│ │/H.264 │70 MB│16-07-24 21:17││/auto~ache│512 B│016-07-27 16:27│ │/ext │ 0 B│16-07-24 22:04││/config │512 B│016-07-27 16:27│ │ Elia~.mp4│18 MB│16-07-31 14:24││/contrib │512 B│016-08-11 20:47│ │ Gise~.mp4│83 MB│16-07-31 13:36││/doc │512 B│016-08-11 20:47│ │ Sala~.mp4│03 MB│16-07-31 16:34││/intl │.5 kB│016-08-11 20:47│ │ Tudo~.mp4│89 MB│16-07-31 14:40││/lib │.5 kB│016-08-11 21:15│ │ bigfile │.1 GB│16-07-30 16:40││/m4 │.0 kB│016-07-27 16:26│ │ bigfile.1│248 B│16-07-30 16:41││/m4.i~lude│.0 kB│016-07-25 23:52│ │ bigf~.bin│.1 GB│16-07-30 16:41││/maint │512 B│016-07-25 23:52│ │ d.mkv │89 MB│16-07-24 20:06││/misc │512 B│016-08-11 20:47│ │ rabb~.mp4│06 MB│3-12-09 18:42 ││/po │.6 kB│016-08-11 21:21│ │ │ │ ││/src │.5 kB│016-08-11 21:22│ │ │ │ ││/tests │512 B│016-08-11 20:47│ ├─ 4.3 GB (43020~) in 11 files ─┤├────────────────────────────────┤ │ rabbi-jacob.mp4 ││UP--DIR │ └───────── 158 GB/187 GB (84%) ─┘└────────── 158 GB/187 GB (84%) ─┘ [mosipov@bsd1home /mediatomb]$ [^] 1Help 2Menu 3View 4Edit 5Copy 6Re~ov 7Mkdir 8De~te 9Pu~Dn
I think this is something one can live with without putting any additional effort to it.
WDYT?
comment:32 in reply to: ↑ 31 ; follow-up: ↓ 34 Changed 8 years ago by egmont
Replying to michael-o:
We have at most 38 chars in default mode/size
If you really want to make it look nice (just as in your screenshots as well as the current implementation) the string would be surrounded by a space, then a horizontal line, then the vertical one. That would mean 34 chars only in a terminal of 80 columns.
This would mean to constantly check and recalculate. Adding additional complexity. Not really favorable.
In my opinion, source code should generally try to be as simple or as complex as required by the desired feature. That is, the desired feature should drive things, and not internal simplicity. There are of course places where you sacrifice a feature for the sake of clean and maintainable code as well as developer resources, or find a reasonable compromise. I don't think an if-else branch (what we'd need here) is such a case. That is, I'd be totally fine with a code that goes like "format this way, check its length, if it's too long then format that way".
I wouldn't do this for two reasons: (1) changes wouldn't look harmonic anymore and people might consider it as a bug when words start to disappear. Moreover, if you mark large directories/files in the first place, you won't see the word "files" at all and will ask yourself: What does this output mean? "100 GB / 1000".
I understand your worries here.
- Continue two lines below in the left (to the left of the disk usage information).
Is this actually possible? My knowledge of ncurses in non-existent.
I really doubt ncurses can do this. I meant to do it "manually", that is, construct two separate strings and make them show up independently from each other at two different parts of the UI.
From my findings, an overflow won't happen but a shorting like "├─ 5,3 MB ~ateien ─┤".
Currently the string is also shortened. The presence of the "~" char clearly informs the user that some data has been stripped and that they need a wider window to fit it all. In this aspect it's okay I guess.
On the other hand, in your examples it happened to strip the last couple of digits of the size (which is kinda usable), but it might actually strip some digits from the middle, or the closing parantheses resulting in an ugly unbalanced pair, or whatever else.
As a compromise between us, how about going for this right now, and opening another bugreport where we ponder about possible better approaches? E.g. I'd prefer the entire exact size disappearing rather than omitting some random digits from a giant number and replacing by tilde.
Thanks!
comment:33 Changed 8 years ago by egmont
... or, when the string gets too long then the scaled and raw numbers could remain in the given row, and the "in 12345 files" could jump two lines below (to the line of disk usage summary), aligned to the left.
comment:34 in reply to: ↑ 32 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
We have at most 38 chars in default mode/size
If you really want to make it look nice (just as in your screenshots as well as the current implementation) the string would be surrounded by a space, then a horizontal line, then the vertical one. That would mean 34 chars only in a terminal of 80 columns.
This would mean to constantly check and recalculate. Adding additional complexity. Not really favorable.
In my opinion, source code should generally try to be as simple or as complex as required by the desired feature. That is, the desired feature should drive things, and not internal simplicity. There are of course places where you sacrifice a feature for the sake of clean and maintainable code as well as developer resources, or find a reasonable compromise. I don't think an if-else branch (what we'd need here) is such a case. That is, I'd be totally fine with a code that goes like "format this way, check its length, if it's too long then format that way".
Agreed, I have to perform some if-else-magic for the three depicted options.
From my findings, an overflow won't happen but a shorting like "├─ 5,3 MB ~ateien ─┤".
Currently the string is also shortened. The presence of the "~" char clearly informs the user that some data has been stripped and that they need a wider window to fit it all. In this aspect it's okay I guess.
On the other hand, in your examples it happened to strip the last couple of digits of the size (which is kinda usable), but it might actually strip some digits from the middle, or the closing parantheses resulting in an ugly unbalanced pair, or whatever else.
Correct, though one has to say that I hardly believe that people will use a terminal smaller than 80x24 in general. Probably even larger.
As a compromise between us, how about going for this right now, and opening another bugreport where we ponder about possible better approaches? E.g. I'd prefer the entire exact size disappearing rather than omitting some random digits from a giant number and replacing by tilde.
Agreed here too. Rather omitting information than have broken one. Ticket is pending.
... or, when the string gets too long then the scaled and raw numbers could remain in the given row, and the "in 12345 files" could jump two lines below (to the line of disk usage summary), aligned to the left.
I am not really sure this is a wise change. The mount point size function has to receive this information though, completely unrelated (bad design). Additionally, the "in x files" would look completely dangling.
Here is a mockup:
Left File Command Options Right ┌<─ /mediatomb ─────────────────────────────.[^]>┐┌<─ ~/Projekte/mc │.n Name │ Size │ Modify time ││.n Name │/.. │ UP--DIR│ 2016-08-11 20:41││/.. │/H.264 │ 170 MB│ 2016-07-24 21:17││/autom4te.cache │/ext │ 0 B│ 2016-07-24 22:04││/config │ Eliane Lim~a BBB.mp4│ 18 MB│ 2016-07-31 14:24││/contrib │ GiselleSec~R.com.mp4│ 483 MB│ 2016-07-31 13:36││/doc │ Salao Moda~ipsbr.mp4│ 503 MB│ 2016-07-31 16:34││/intl │ TudoPelaAu~ipsBR.mp4│ 289 MB│ 2016-07-31 14:40││/lib │ bigfile │ 1.1 GB│ 2016-07-30 16:40││/m4 │ bigfile.1 │ 248 B│ 2016-07-30 16:41││/m4.include │ bigfile.bin │ 1.1 GB│ 2016-07-30 16:41││/maint │ d.mkv │ 189 MB│ 2016-07-24 20:06││/misc │ rabbi-jacob.mp4 │ 506 MB│2013-12-09 18:42 ││/po │ │ │ ││/src │ │ │ ││/tests │ │ │ ││ 0001-.po-R~le-t │ │ │ ││ 0001-size_~ixes │ │ │ ││ 0002-size_~appl │ │ │ ││ ABOUT-NLS │ │ │ ││ AUTHORS │ │ │ ││@COPYING │ │ │ ││ ChangeLog │ │ │ ││@INSTALL │ │ │ ││ Makefile ├────────────── 4.3 GB (4302077093 B) ───────────┤├──────────────── │ rabbi-jacob.mp4 ││UP--DIR └─ in 11 files ──────────── 158 GB/187 GB (84%) ─┘└────────────────
It pretty much looks like "rabbi-jacob.mp4" is contained/split into 11 files and not having 4.3 GB in 11 files. I'd rather see ommitting raw value here.
comment:35 Changed 8 years ago by michael-o
Can someone kindly purge the attachments? One patch is merged and the rest is already overhauled due to our discussions. I will provide updated patches soon.
comment:36 follow-up: ↓ 38 Changed 8 years ago by michael-o
I'd like to summarize our current discussion with Egmont to avoid misunderstandings:
- The pending changes for size_trunc() and size_trunc_len(), which are used throughout the code, will be applied to the feature branch. (necessary for further changes)
- size_trunc_sep() will be deprecated and not used anymore (don't know how to mark a function as deprecated in your documentation style)
- display_total_marked_size() will receive an update in such that it will apply the three modes depicted in comment 29. A new panel option "Total marked size style: [raw, scaled, both]" will make this possible. (need to investigate how to do this)
After this has been done, other spots will be taken on:
- Update label "Use SI size units" to "Use SI prefixes instead of IEC ones" (which reflects the correct terms and new reality), though I would rather see: "Size prefix style: [IEC, SI]" with leaving the config file as-is for maximum compat.
- Reconsider wether the info panel should show a scaled or raw value
- Update documentation
Please confirm.
comment:37 Changed 8 years ago by michael-o
Outstanding merges:
- Missing translations in po files
- Remove redundant words in po files
- Implement auto-scaling in size_trunc_*()
Git-formatted patches can be provided on request.
comment:38 in reply to: ↑ 36 ; follow-up: ↓ 40 Changed 8 years ago by andrew_b
I think we should realize the ticket topic here, i. e. fix the "Improper use of IEC and SI prefixes". All other beyond that is the topic of another ticket.
comment:39 Changed 8 years ago by andrew_b
Branch rebased: [64af299b91eb397fa7af70fc5c13aa3b153aff8c].
comment:40 in reply to: ↑ 38 ; follow-up: ↓ 41 Changed 8 years ago by michael-o
Replying to andrew_b:
I think we should realize the ticket topic here, i. e. fix the "Improper use of IEC and SI prefixes". All other beyond that is the topic of another ticket.
Can you be more precise? What would you like to discuss in another ticket? I will spawn them.
comment:41 in reply to: ↑ 40 ; follow-up: ↓ 47 Changed 8 years ago by andrew_b
Replying to michael-o:
Can you be more precise? What would you like to discuss in another ticket?
Everything about display of full/scaled sizes, new options, etc. All but fix of IEC and SI prefixes usage.
comment:47 in reply to: ↑ 41 ; follow-up: ↓ 49 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to michael-o:
Can you be more precise? What would you like to discuss in another ticket?
Everything about display of full/scaled sizes, new options, etc. All but fix of IEC and SI prefixes usage.
As requested, I have created issues #3673, #3674, #3675, #3676, #3677. I will provide patches for those as soon as this issue has been completed.
Please tell me how we will continue with the outstanding merges.
comment:48 follow-up: ↓ 51 Changed 8 years ago by andrew_b
- Blocking 3677 removed
comment:49 in reply to: ↑ 47 ; follow-up: ↓ 50 Changed 8 years ago by andrew_b
Replying to michael-o:
with the outstanding merges.
I'm not quite understanding you. What do you mean?
comment:50 in reply to: ↑ 49 ; follow-up: ↓ 52 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to michael-o:
with the outstanding merges.
I'm not quite understanding you. What do you mean?
Outstanding merges from comment:37, they are necessary to complete the change codewise. The current patch applied by you to the branch is one of several.
comment:51 in reply to: ↑ 48 Changed 8 years ago by michael-o
comment:52 in reply to: ↑ 50 ; follow-up: ↓ 53 Changed 8 years ago by andrew_b
Replying to michael-o:
Outstanding merges from comment:37, they are necessary to complete the change codewise. The current patch applied by you to the branch is one of several.
- As I wrote in comment:10, patches for *.po are superfluous. All translation updates are made by native language translation teams via www.transifex.com.
- The replacement of size_trunc_sep() by size_trunc() with autoscaling is out-of-topic here. Probably, #3674 is better place for that.
comment:53 in reply to: ↑ 52 ; follow-up: ↓ 54 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to michael-o:
Outstanding merges from comment:37, they are necessary to complete the change codewise. The current patch applied by you to the branch is one of several.
- As I wrote in comment:10, patches for *.po are superfluous. All translation updates are made by native language translation teams via www.transifex.com.
I am aware of that but if you take a closer look at commit bfcf1509295704e5a4ea260032f199027cb18604 you see that it removes redundant words not present in the English po file. You can drop the second one if you want to wait for the translation team.
- The replacement of size_trunc_sep() by size_trunc() with autoscaling is out-of-topic here. Probably, #3674 is better place for that.
size_trunc_sep() does mere add grouping, it does not scale anything. I do now understand what you are after now, you want the stuff completely seperated. This is fine. Morever, #3674 isn't the right place since it already requries the scaler implementation. I will spawn an new ticket for that.
Though, it is still not complete, free/total size is still wrong and all other places where size_trunc_len() is used. This needs an additional commit.
Real world example:
Left File Command Options Right ┌────────────────── Information ──────────────────┐┌<─ /home ───────────────────────────────────.[^]>┐ │ Midnight Commander 4.8.17-81-gd4d5be2 ││.n Name │ Size │ Modify time │ ├─────────────────────────────────────────────────┤│/.. │UP--DIR│17. Aug 15:50│ │ File: osipovmi ││/ideasswe │ 512│ 08. Apr 2013│ │ Location: 67h:30180h ││/matthias │ 1536│10. Jun 16:20│ │ Mode: drwxr-x--- (0750) ││/osipovmi │ 1523M│ 15. Oct 2015│ │ Links: 3 ││/uweb │ 512│ 19. Jan 2012│ │ Owner: osipovmi/cad ││/zabbix │ 512│ 30. May 2014│ │ Size: 1559847K (8 blocks) ││ │ │ │ │ Changed: 15. Oct 2015 ││ │ │ │ │ Modified: 15. Oct 2015 ││ │ │ │ │ Accessed: 18. Aug 14:18 ││ │ │ │ │ Filesystem: /usr/home ││ │ │ │ │ Device: /dev/gvinum/home │├──────────── 1,559,847 KiB in 1 file ────────────┤ │ Type: ufs ││/osipovmi │ └─────────────────────────────────────────────────┘└───────────────────────────── 1970M/3967M (49%) ─┘ Hint: Want to do complex searches? Use the External Panelize command. $ [^] 1Help 2Menu 3View 4Edit 5Copy 6RenMov 7Mkdir 8Delete 9PullDn 10Quit
comment:54 in reply to: ↑ 53 ; follow-up: ↓ 55 Changed 8 years ago by andrew_b
Replying to michael-o:
size_trunc_sep() does mere add grouping, it does not scale anything.
Probably, I tested wrong patch. Could you please provide a final correct patch(es) on top of [64af299b91eb397fa7af70fc5c13aa3b153aff8c] without ant changes in po/?
comment:55 in reply to: ↑ 54 ; follow-up: ↓ 56 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to michael-o:
size_trunc_sep() does mere add grouping, it does not scale anything.
Probably, I tested wrong patch. Could you please provide a final correct patch(es) on top of [64af299b91eb397fa7af70fc5c13aa3b153aff8c] without ant changes in po/?
Yes, I will refactor the outstanding merge and provide a patch w/o scaling but with unit fixes. This is what you want to see, right?
comment:56 in reply to: ↑ 55 Changed 8 years ago by andrew_b
comment:57 Changed 8 years ago by michael-o
Patch is almost done. I am testing it right now on several OSes.
Changed 8 years ago by michael-o
- Attachment 0001-Ticket-3666-Improper-use-of-IEC-and-SI-prefixes-for-.2.patch added
comment:58 follow-up: ↓ 59 Changed 8 years ago by michael-o
Here is the patch to make visuals sound. Documentation is up for next week.
Please review and apply. Patch has been testedn on FreeBSD 9.3/10.3, Ubuntu 14.04 LTS and CentOS 7.
Also please note that I won't be able to reply until end of next week.
comment:59 in reply to: ↑ 58 ; follow-up: ↓ 60 Changed 8 years ago by andrew_b
- static const char *const suffix[] = { "", "K", "M", "G", "T", "P", "E", "Z", "Y", NULL };
- static const char *const suffix_lc[] = { "", "k", "m", "g", "t", "p", "e", "z", "y", NULL };
+ static const char *const units_iec[] = { "B", "KiB", "MiB", "GiB", NULL };
+ static const char *const units_si[] = { "B", "kB", "MB", "GB", NULL };
Why do you drop "T", "P", "E", "Z", "Y"?
- g_snprintf (buffer, len + 1, "%" PRIuMAX "%s", size, sfx[j]); + g_snprintf (buffer, len + 1, "%" PRIuMAX " %s", size, _(sfx[j]));
sfx[j] is not i18n'd. To be i18n'd, it must be marked using the N_() macro:
static const char *const units_iec[] = { N_("B"), N_("KiB)", N_("MiB)", N_("GiB"), NULL };
static const char *const units_si[] = { N_("B"), N_("kB"), N_("MB"), N_("GB"), NULL };
comment:60 in reply to: ↑ 59 Changed 8 years ago by michael-o
Replying to andrew_b:
- static const char *const suffix[] = { "", "K", "M", "G", "T", "P", "E", "Z", "Y", NULL }; - static const char *const suffix_lc[] = { "", "k", "m", "g", "t", "p", "e", "z", "y", NULL }; + static const char *const units_iec[] = { "B", "KiB", "MiB", "GiB", NULL }; + static const char *const units_si[] = { "B", "kB", "MB", "GB", NULL };Why do you drop "T", "P", "E", "Z", "Y"?
There are no gettext ids in the po files for them. If they will use the key by default, I will readd them. Though, I highly doubt that anything above PB will be displayed as volume size in the near future. Do you want me to readd them? No issue.
- g_snprintf (buffer, len + 1, "%" PRIuMAX "%s", size, sfx[j]); + g_snprintf (buffer, len + 1, "%" PRIuMAX " %s", size, _(sfx[j]));sfx[j] is not i18n'd. To be i18n'd, it must be marked using the N_() macro:
static const char *const units_iec[] = { N_("B"), N_("KiB)", N_("MiB)", N_("GiB"), NULL }; static const char *const units_si[] = { N_("B"), N_("kB"), N_("MB"), N_("GB"), NULL };
Good catch. The official docs of gettext are lousy here. They do not really explain the purpose of N_() while this does. I will modify the patch, of course.
Changed 8 years ago by michael-o
- Attachment 0001-Ticket-3666-Improper-use-of-IEC-and-SI-prefixes-for-.3.patch added
comment:61 Changed 8 years ago by michael-o
As discussed, I have uploaded a corrected patch.
Changed 8 years ago by michael-o
- Attachment 0001-Ticket-3666-Improper-use-of-IEC-and-SI-prefixes-for-.4.patch added
Updated documentation (man pages)
comment:62 follow-up: ↓ 63 Changed 8 years ago by andrew_b
All patches was applied.
Branch: 3666_iec_si_prefixes.
Initial changeset:a2a5aec6a5fa91a209d7f12f8cf5427e34cafe4a
Please review.
comment:63 in reply to: ↑ 62 Changed 8 years ago by michael-o
Replying to andrew_b:
All patches was applied.
Branch: 3666_iec_si_prefixes.
Initial changeset:a2a5aec6a5fa91a209d7f12f8cf5427e34cafe4a
Please review.
Reviewed and tested on FreeBSD 9.3/10.3 and RHEL 6. All is nice. Though, there are still po errors/lefteovers which need to be addressed. I am not talking about missing translations.
comment:64 follow-up: ↓ 66 Changed 8 years ago by zaytsev
Regarding the suffixes, ~100 PB libraries are not uncommon these days (my personal experience), so, I'm afraid, EBs are not that far away. I'm not sure what's the advantage of leaving them and the remaining prefixes out. Are there any? If not, maybe we could keep them? Otherwise, no objections.
Though, there are still po errors/lefteovers which need to be addressed.
Hmmm, I'm completely confused. What errors/leftovers are you talking about? Anything that is not addressed in new tickets and prevents this branch from being merged?
P.S. I can delete the attachments from this ticket if this request still stands.
comment:66 in reply to: ↑ 64 Changed 8 years ago by michael-o
Replying to zaytsev:
Regarding the suffixes, ~100 PB libraries are not uncommon these days (my personal experience), so, I'm afraid, EBs are not that far away. I'm not sure what's the advantage of leaving them and the remaining prefixes out. Are there any? If not, maybe we could keep them? Otherwise, no objections.
We can, of course, reintroduce them. That would require some po changes as well too. If you really see a need for them, I will attach another patch, though I cannot test such numbers reasonably.
Though, there are still po errors/lefteovers which need to be addressed.
Hmmm, I'm completely confused. What errors/leftovers are you talking about? Anything that is not addressed in new tickets and prevents this branch from being merged?
This patch is missing, though I have written it several times. Andrey refused to accept it:
diff --git a/po/de.po b/po/de.po index 9cb2815..a81a111 100644 --- a/po/de.po +++ b/po/de.po @@ -3540,8 +3540,8 @@ msgstr "<readlink fehlgeschlagen>" #, c-format msgid "%s in %d file" msgid_plural "%s in %d files" -msgstr[0] "%s Bytes in %d Datei" -msgstr[1] "%s Bytes in %d Dateien" +msgstr[0] "%s in %d Datei" +msgstr[1] "%s in %d Dateien" msgid "Panelize" msgstr "Anordnen" diff --git a/po/fr.po b/po/fr.po index b9f3f1d..d5fc4ea 100644 --- a/po/fr.po +++ b/po/fr.po @@ -3441,7 +3441,7 @@ msgstr "<échec de readlink>" #, c-format msgid "%s in %d file" msgid_plural "%s in %d files" -msgstr[0] " %s octets dans %d fichier" +msgstr[0] " %s dans %d fichier" msgstr[1] "%s dans %d fichiers" msgid "Panelize" diff --git a/po/it.po b/po/it.po index 3206ec9..76d1452 100644 --- a/po/it.po +++ b/po/it.po @@ -3529,8 +3529,8 @@ msgstr "<readlink fallito>" #, c-format msgid "%s in %d file" msgid_plural "%s in %d files" -msgstr[0] " %s byte in %d file" -msgstr[1] " %s byte in %d file" +msgstr[0] "" +msgstr[1] "" msgid "Panelize" msgstr "Pannellizza" diff --git a/po/nl.po b/po/nl.po index 6db51e1..53ac8a3 100644 --- a/po/nl.po +++ b/po/nl.po @@ -3525,8 +3525,8 @@ msgstr "<readlink mislukt>" #, c-format msgid "%s in %d file" msgid_plural "%s in %d files" -msgstr[0] "%s bytes in %d bestand" -msgstr[1] "%s bytes in %d bestand(en)" +msgstr[0] "%s in %d bestand" +msgstr[1] "%s in %d bestand(en)" msgid "Panelize" msgstr "Als venster" diff --git a/po/sk.po b/po/sk.po index fbc6845..620d78e 100644 --- a/po/sk.po +++ b/po/sk.po @@ -3535,9 +3535,9 @@ msgstr "<čítanie odkazu zlyhalo>" #, c-format msgid "%s in %d file" msgid_plural "%s in %d files" -msgstr[0] "%s bajt v %d súboroch" -msgstr[1] "%s bajty v %d súboroch" -msgstr[2] "%s bajtov v %d súboroch" +msgstr[0] "%s v %d súboroch" +msgstr[1] "%s v %d súboroch" +msgstr[2] "%s v %d súboroch" msgid "Panelize" msgstr "Panelizovať"
comment:68 follow-up: ↓ 69 Changed 8 years ago by zaytsev
This patch is missing, though I have written it several times. Andrey refused to accept it:
Right, I see. This will have to be done on Transifex immediately after this branch is merged.
We can, of course, reintroduce them. That would require some po changes as well too. If you really see a need for them, I will attach another patch, though I cannot test such numbers reasonably.
Yes, please!
comment:69 in reply to: ↑ 68 Changed 8 years ago by michael-o
Replying to zaytsev:
This patch is missing, though I have written it several times. Andrey refused to accept it:
Right, I see. This will have to be done on Transifex immediately after this branch is merged.
We can, of course, reintroduce them. That would require some po changes as well too. If you really see a need for them, I will attach another patch, though I cannot test such numbers reasonably.
Yes, please!
Here is the patch:
diff --git a/lib/util.c b/lib/util.c
index 3d497cf..3e4697d 100644
--- a/lib/util.c
+++ b/lib/util.c
@@ -450,9 +450,9 @@ size_trunc_len (char *buffer, unsigned int len, uintmax_t size, int units, gbool
};
/* *INDENT-ON* */
static const char *const units_iec[] = { N_("B"), N_("KiB"), N_("MiB"), N_("GiB"), N_("TiB"),
- N_("PiB"), NULL };
+ N_("PiB"), N_("EiB"), N_("ZiB"), N_("YiB"), NULL };
static const char *const units_si[] = { N_("B"), N_("kB"), N_("MB"), N_("GB"), N_("TB"),
- N_("PB"), NULL };
+ N_("PB"), N_("EB"), N_("ZB"), N_("YB"), NULL };
const char *const *sfx = use_si ? units_si : units_iec;
int j = 0;
Is that sufficient? as far as I understood gettext, the msgids can be produced with a simple command.
comment:70 follow-up: ↓ 71 Changed 8 years ago by andrew_b
Patch was applied.
Branch was rebased to current master: [bb019cd8822ff4870b656eb9425dd897417efda9].
Please review.
It's clean that "4096" is 4096 bytes. Now it's displayed as "4096 B". I'd personally prefer do not display the "B" suffix, but I'm not insisting.
comment:71 in reply to: ↑ 70 Changed 8 years ago by michael-o
Replying to andrew_b:
Patch was applied.
Branch was rebased to current master: [bb019cd8822ff4870b656eb9425dd897417efda9].
Please review.
Thanks for merging. I will check this on several operating systems next week.
It's clean that "4096" is 4096 bytes. Now it's displayed as "4096 B". I'd personally prefer do not display the "B" suffix, but I'm not insisting.
To be honest, it is not clean or clear what is implied. I think there is no need to imply anything but simply state it, avoiding any interpretation. Additionally, on a subsequent ticket, I will try to address that making it autoscale.
comment:72 Changed 8 years ago by michael-o
Just tried latest HEAD of that branch on RHEL 6 and FreeBSD 9.3-STABLE. Works as expected. It is ready to be merged.
comment:73 Changed 8 years ago by andrew_b
- Votes for changeset set to andrew_b
- Branch state changed from on review to approved
comment:74 Changed 8 years ago by andrew_b
- Status changed from accepted to testing
- Votes for changeset changed from andrew_b to committed-master
- Resolution set to fixed
- Branch state changed from approved to merged
Merged to master: 1cccd80399abaff8f4c02952e4ad969d2ae4e03c
git log --pretty=oneline c2e1ec8..1cccd80
comment:76 Changed 8 years ago by michael-o
Thank you guys, master works as expected on RHEL 6 and FreeBSD 9.3-STABLE.
comment:77 Changed 8 years ago by michael-o
Even tried on HP-UX 11.31. It just works.
comment:78 Changed 8 years ago by zaytsev
FYI, I have applied the translations patch via Transifex.
comment:79 follow-up: ↓ 80 Changed 8 years ago by egmont
Houston!
Beginning with bae814d0d48dbb8eae48231f13e8aaec544178d8 mcview segfaults at startup.
comment:80 in reply to: ↑ 79 ; follow-up: ↓ 81 Changed 8 years ago by andrew_b
Replying to egmont:
Beginning with bae814d0d48dbb8eae48231f13e8aaec544178d8 mcview segfaults at startup.
lib/util.c:
511 if (size < power10[len - (1 + 6)])
The index is negative here: in case of len == 5 we have power10[-2].
comment:81 in reply to: ↑ 80 ; follow-ups: ↓ 82 ↓ 83 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to egmont:
Beginning with bae814d0d48dbb8eae48231f13e8aaec544178d8 mcview segfaults at startup.
lib/util.c:
511 if (size < power10[len - (1 + 6)])The index is negative here: in case of len == 5 we have power10[-2].
Thanks for test. Which buffer did I miss to increase? Who is passing 5?
Can you give a sample input?
I just rechecked the code and am not able to find a too small buffer which is allocated statically.
comment:82 in reply to: ↑ 81 ; follow-up: ↓ 84 Changed 8 years ago by andrew_b
Replying to michael-o:
Thanks for test. Which buffer did I miss to increase? Who is passing 5?
The viewer.
Can you give a sample input?
Run mc. Press F3 on any file.
#0 0x000000000045c956 in size_trunc_len (buffer=0x7fffffffd830 "┐", len=5, size=131, units=0, use_si=0) at /home/borodin/work/work.c/mc/mc-master/lib/util.c:511 #1 0x00000000004d04d8 in mcview_display_status (view=0x81f570) at /home/borodin/work/work.c/mc/mc-master/src/viewer/display.c:177 #2 0x00000000004d0762 in mcview_display (view=0x81f570) at /home/borodin/work/work.c/mc/mc-master/src/viewer/display.c:258
comment:83 in reply to: ↑ 81 Changed 8 years ago by egmont
Replying to michael-o:
I just rechecked the code and am not able to find a too small buffer which is allocated statically.
Even if there wasn't such a code right now, it'd still be a good idea to code defensively and add upper and lower safe-guards so that no sane caller can cause this method to crash.
Thanks guys for looking into this! :)
comment:84 in reply to: ↑ 82 ; follow-up: ↓ 85 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to michael-o:
Thanks for test. Which buffer did I miss to increase? Who is passing 5?
The viewer.
Can you give a sample input?
Run mc. Press F3 on any file.
#0 0x000000000045c956 in size_trunc_len (buffer=0x7fffffffd830 "┐", len=5, size=131, units=0, use_si=0) at /home/borodin/work/work.c/mc/mc-master/lib/util.c:511 #1 0x00000000004d04d8 in mcview_display_status (view=0x81f570) at /home/borodin/work/work.c/mc/mc-master/src/viewer/display.c:177 #2 0x00000000004d0762 in mcview_display (view=0x81f570) at /home/borodin/work/work.c/mc/mc-master/src/viewer/display.c:258
Strange thing, I tried current master on RHEL 6 and FreeBSD 9.3-STABLE and had no segfault on neither small nor large files. Anyway, thank you for testing. No idea why I have missed that static buffer. Patch attached.
comment:85 in reply to: ↑ 84 ; follow-up: ↓ 86 Changed 8 years ago by andrew_b
Replying to michael-o:
Patch attached.
Actually, this patch doesn't fix the bug. The bug is here:
511 if (size < power10[len - (1 + 6)])
size_trunc_len() is just unable to work with buffers smaller than 7 bytes.
comment:86 in reply to: ↑ 85 ; follow-up: ↓ 87 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to michael-o:
Patch attached.
Actually, this patch doesn't fix the bug. The bug is here:
511 if (size < power10[len - (1 + 6)])size_trunc_len() is just unable to work with buffers smaller than 7 bytes.
This is correct. The unfortunately no way to tell the caller that the buffer is too small. I have properly documented by it has to be at least seven bytes long.
comment:87 in reply to: ↑ 86 ; follow-up: ↓ 88 Changed 8 years ago by egmont
Replying to michael-o:
The attached patch makes the segfault go away for me, thanks!
The unfortunately no way to tell the caller that the buffer is too small.
You could (or rather: you should :)) add an assert() call. This way if someone invokes the method with a too small buffer, we at least get a kinda informative error message rather than a potential data corruption or segfault somewhere later on (depending on other conditions such as architecture, OS, compiler flags etc.).
I have properly documented by it has to be at least seven bytes long.
I'm sorry but I cannot find this being documented (I'm looking above the declaration and definition of size_trunc_len() in lib/util.[hc], I guess if anywhere then it should be documented here).
comment:88 in reply to: ↑ 87 ; follow-up: ↓ 89 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
The attached patch makes the segfault go away for me, thanks!
The unfortunately no way to tell the caller that the buffer is too small.
You could (or rather: you should :)) add an assert() call. This way if someone invokes the method with a too small buffer, we at least get a kinda informative error message rather than a potential data corruption or segfault somewhere later on (depending on other conditions such as architecture, OS, compiler flags etc.).
You are right, here is a possible patch:
diff --git a/lib/util.c b/lib/util.c
index 3356c36..92e7ab3 100644
--- a/lib/util.c
+++ b/lib/util.c
@@ -414,6 +414,10 @@ size_trunc_sep (uintmax_t size, gboolean use_si)
void
size_trunc_len (char *buffer, unsigned int len, uintmax_t size, int units, gboolean use_si)
{
+#ifdef HAVE_ASSERT_H
+ assert (len >= 7 && sizeof(buffer) > 7);
+#endif
+
/* Avoid taking power for every file. */
/* *INDENT-OFF* */
static const uintmax_t power10[] = {
This should be idiotproof. Please review.
I have properly documented by it has to be at least seven bytes long.
I'm sorry but I cannot find this being documented (I'm looking above the declaration and definition of size_trunc_len() in lib/util.[hc], I guess if anywhere then it should be documented here).
I have done it inline but missed that, right. Here is the proposed patch:
diff --git a/lib/util.c b/lib/util.c index 3356c36..24a337e 100644 --- a/lib/util.c +++ b/lib/util.c @@ -403,8 +403,8 @@ size_trunc_sep (uintmax_t size, gboolean use_si) /* --------------------------------------------------------------------------------------------- */ /** * Print file SIZE to BUFFER, but don't exceed LEN characters, - * not including trailing 0. BUFFER should be at least LEN+1 long. - * This function is called for every file on panels, so avoid + * not including trailing 0. LEN should be at least 7 long and BUFFER at least + * LEN+1 long. This function is called for every file on panels, so avoid * floating point by any means. * * Units: size units (filesystem sizes are 1K blocks) diff --git a/lib/util.h b/lib/util.h index af4022e..db933fa 100644 --- a/lib/util.h +++ b/lib/util.h @@ -147,7 +147,8 @@ const char *size_trunc (uintmax_t size, gboolean use_si); const char *size_trunc_sep (uintmax_t size, gboolean use_si); /* Print file SIZE to BUFFER, but don't exceed LEN characters, - * not including trailing 0. BUFFER should be at least LEN+1 long. + * not including trailing 0. LEN should be at least 7 long and BUFFER at least + * LEN+1 long. * * Units: size units (0=bytes, 1=Kbytes, 2=Mbytes, etc.) */ void size_trunc_len (char *buffer, unsigned int len, uintmax_t size, int units, gboolean use_si);
If all of the above is satisfying, I would create proper Git-formatted patches with commit messages.
comment:89 in reply to: ↑ 88 ; follow-up: ↓ 90 Changed 8 years ago by andrew_b
Replying to michael-o:
diff --git a/lib/util.c b/lib/util.c
index 3356c36..92e7ab3 100644
--- a/lib/util.c
+++ b/lib/util.c
@@ -414,6 +414,10 @@ size_trunc_sep (uintmax_t size, gboolean use_si)
void
size_trunc_len (char *buffer, unsigned int len, uintmax_t size, int units, gboolean use_si)
{
+#ifdef HAVE_ASSERT_H
+ assert (len >= 7 && sizeof(buffer) > 7);
+#endif
+
/* Avoid taking power for every file. */
/* *INDENT-OFF* */
static const uintmax_t power10[] = {
sizeof(buffer) is not size of buffer. sizeof(buffer) == sizeof(char *) == 4 or 8 (in 32- and 64-bit platform respectively).
comment:90 in reply to: ↑ 89 ; follow-ups: ↓ 91 ↓ 92 Changed 8 years ago by michael-o
Replying to andrew_b:
Replying to michael-o:
diff --git a/lib/util.c b/lib/util.c index 3356c36..92e7ab3 100644 --- a/lib/util.c +++ b/lib/util.c @@ -414,6 +414,10 @@ size_trunc_sep (uintmax_t size, gboolean use_si) void size_trunc_len (char *buffer, unsigned int len, uintmax_t size, int units, gboolean use_si) { +#ifdef HAVE_ASSERT_H + assert (len >= 7 && sizeof(buffer) > 7); +#endif + /* Avoid taking power for every file. */ /* *INDENT-OFF* */ static const uintmax_t power10[] = {sizeof(buffer) is not size of buffer. sizeof(buffer) == sizeof(char *) == 4 or 8 (in 32- and 64-bit platform respectively).
Stupid me, yes. It give the size of the pointer only. Since we do not know whether the buffer is statically or dynamically, is there a better way to check the size? I am not a day-to-day C hacker. I think one has to rely on length and the precondition described in the docs.
comment:91 in reply to: ↑ 90 Changed 8 years ago by andrew_b
Replying to michael-o:
is there a better way to check the size?
The size of array is the 'len + 1', as described in function description.
assert() itself is not a segfault protection. I think that size_trunc_len() mustn't segfault with small buffer. If buffer is too small, it can be filled with some non-numerical value (say, "????", or "----", or something else) in order to show that requested size cannot be printed correctly.
comment:92 in reply to: ↑ 90 ; follow-up: ↓ 93 Changed 8 years ago by egmont
Replying to michael-o:
Stupid me, yes. It give the size of the pointer only. Since we do not know whether the buffer is statically or dynamically, is there a better way to check the size?
Nope, at least not with bare C strings (char[] vs. char*). You could go with higher level solutions such as GString, in which case you wouldn't need to pass the length separately. Not sure how much mc uses this or not.
As long as the pointer and the length are passed separately, it's reasonable to do the assertion on the `length' parameter only.
Replying to andrew_b:
assert() itself is not a segfault protection.
Why? The entire program aborts on a failed assertion, doesn't it? (If assertions are enabled, of course.) Assertions are meant to catch situations that are clearly internal programming errors, such as calling a method with arguments that do not comply with the method's documentation.
I think that size_trunc_len() mustn't segfault with small buffer.
It's not a black and white story. You can choose to go with a method documentation that requires a buffer of at least 7 bytes and then an assertion is okay. Or you can choose to allow a smaller buffer and fill up with whatever placeholder characters (but still mention in the documentation that the caller shouldn't expect a "usable" result in that case). In this particular case I'm fine with either approach.
comment:93 in reply to: ↑ 92 Changed 8 years ago by andrew_b
- Status changed from closed to reopened
- Votes for changeset committed-master deleted
- Resolution fixed deleted
- Branch state changed from merged to no branch
Replying to egmont:
Replying to andrew_b:
assert() itself is not a segfault protection.
Why?
Unexpected abort is better then segfault but isn't a nice thing itself. When you have open and not saved file(s), no matter for you what happened, assert or segfault. (Yes we have many asserts in mc code base, but it is another story.)
I think that size_trunc_len() mustn't segfault with small buffer.
It's not a black and white story. You can choose to go with a method documentation that requires a buffer of at least 7 bytes and then an assertion is okay.
Ok, let it be.
comment:94 Changed 8 years ago by andrew_b
- Version changed from 4.8.17 to master
- Branch state changed from no branch to on review
Branch: 3666_iec_si_prefixes_fix
changeset:b29ab1038965978d9b238bf75f792ad7b4bc9865
comment:95 Changed 8 years ago by zaytsev-work
Extra "This function is called for every file on panels, so avoid".
comment:96 Changed 8 years ago by andrew_b
If there are no any objections I will merge 3666_iec_si_prefixes_fix into master today to fix segfault soon.
comment:97 Changed 8 years ago by zaytsev
- Votes for changeset set to zaytsev
- Branch state changed from on review to approved
comment:98 Changed 8 years ago by andrew_b
- Status changed from reopened to closed
- Votes for changeset changed from zaytsev to committed-master
- Resolution set to fixed
- Branch state changed from approved to merged
Merged to master: [7374b9c62681487d2735d6d490d78b33657ce0ea].
comment:99 follow-up: ↓ 100 Changed 8 years ago by egmont
Houston take 2!
It segfaults The brand new assertion is hit if the terminal window is made narrower than 48 columns.
comment:100 in reply to: ↑ 99 Changed 8 years ago by michael-o
Replying to egmont:
Houston take 2!
It segfaultsThe brand new assertion is hit if the terminal window is made narrower than 48 columns.
How? The memory is fixed-size. What is your OS?
comment:101 follow-up: ↓ 104 Changed 8 years ago by egmont
panel.c: string_file_size() is called with a len parameter that's less than 4, which in turn is increased by 3 (why? that step is totally unclear to me) and then passed to size_trunc_len().
I'm on Ubuntu Yakkety, but I don't think it matters.
comment:102 follow-up: ↓ 103 Changed 8 years ago by zaytsev
Wow, Egmont, you are an ace tester! Thank you.
comment:103 in reply to: ↑ 102 Changed 8 years ago by michael-o
comment:104 in reply to: ↑ 101 Changed 8 years ago by michael-o
Replying to egmont:
panel.c: string_file_size() is called with a len parameter that's less than 4, which in turn is increased by 3 (why? that step is totally unclear to me) and then passed to size_trunc_len().
4? Is t supposed to be 8+3. 3 is added here intentionally because of multibyte chars. Otherwise they won't fit. I cannot add 3 upfront because the column would be wider than necessary. This is a typical bytesize vs. charsize problem in C.
I will try to reproduce this on RHEL 6 via SSH later this day.
I'm on Ubuntu Yakkety, but I don't think it matters.
comment:105 Changed 8 years ago by andrew_b
I want back to may offer in the comment:91:
If buffer is too small, it can be filled with some non-numerical value (say, "????", or "----", or something else) in order to show that requested size cannot be printed correctly.
comment:106 Changed 8 years ago by egmont
(Disclaimer: I'm writing this comment without looking at the code.)
I feel too much confusion...
You add 3 because... why 3? Sounds like you're expecting every character of "MiB" and friends to be transcribed to let's say Russian. How about CJK (3 bytes per character), Vietnamese (they use a lot of combining character as far as I know) etc. scripts? How do you know that they don't need more?
The code, without a comment right there about this "+ 3" IMO cannot be understood.
You previously called this 'len', add 3, and still call it 'len'. This is a very bad concept. Mandatory read: http://www.joelonsoftware.com/articles/Wrong.html.
The two most important concepts needed in mc are the length in bytes when encoded in UTF-8 (usually called 'len' or 'length') and the width it occupies on the screen aka. the number of cells (usually called 'width'). They are quite loosely coupled: a Unicode codepoint can take anywhere from 1 to 4 bytes in UTF-8, and can occupy anywhere from 0 to 2 character cells.
In the spirit of the aforementioned article, if you add 3 because of the UTF-8 encoding as well as varying display width of characters (and if this is indeed the right way of doing the maths which I really doubt) then the variable should be called 'width' before incrementing, and 'len' afterwards.
Now, I think I would probably get rid of passing 'len' (the buffer length in bytes) across these methods. It usually makes sense if the data to be stored there can be arbitrarily large (or quite large) and you don't always want to entirely store it. This is not the case here. The "tiny" bufsize (64) is a safe upper limit, a file size suffixed by units will always fit in all locales (or if not because of non-latin digits for some locale, we can just increase the tiny bufsize). I think it's okay to say in all these methods that the caller is expected to give a large enough buffer that can store the output, and make the code simpler by not communicating the actual buffer size. There's absolutely no point in trying to save a couple of bytes by allocating smaller buffers.
As for formatting for a given available width on the screen, there are two possible approaches I can imagine, and I'd need to check the code to see which one it does.
One possibility is that the method that formats the number doesn't care about the width, and it's the caller that somehow truncates it afterwards if it turns out to be too wide. I guess this approach is okay, although not as flexible as the other.
The other possibility is that the method that formats the number knows the available width. As such, in this case this method needs to know the 'width' as a parameter, rather than 'len', which is something that being incremented by 3 because of UTF-8 just when calling this method is obviously totally wrong.
I hope this comment helps coming up with a cleaner design and implementation. Thanks guys for working on this! :)
comment:107 follow-up: ↓ 108 Changed 8 years ago by michael-o
Replying to andrew_b:
I want back to may offer in the comment:91:
If buffer is too small, it can be filled with some non-numerical value (say, "????", or "----", or something else) in order to show that requested size cannot be printed correctly.
You are probably right, but I still would like to understand how this issue has happened at all. It is called within these two blocks
{
"size", 8, FALSE, J_RIGHT,
/* TRANSLATORS: one single character to represent 'size' sort mode */
/* TRANSLATORS: no need to translate 'sort', it's just a context prefix */
N_("sort|s"),
N_("&Size"), TRUE, TRUE,
string_file_size,
(GCompareFunc) sort_size
}
,
{
"bsize", 8, FALSE, J_RIGHT,
"",
N_("Block Size"), FALSE, FALSE,
string_file_size_brief,
(GCompareFunc) sort_size
}
and the buffer is
static char buffer[BUF_TINY];
Surprisingly, this works as expected on FreeBSD, but I was able to force the segfault on RHEL 6. This must be some "Linux" feature. I will try to locate the core file and load it into GDB.
comment:108 in reply to: ↑ 107 ; follow-up: ↓ 111 Changed 8 years ago by egmont
Replying to michael-o:
This must be some "Linux" feature.
Nope, sorry, this is not a "Linux feature", this is a bug in the code.
Rule of thumb: a segfault (especially if reproducible by multiple developers) has a perhaps about 99.99% chance of being a bug in the code (or in a library underneath that it calls), and about 0.01% of being some OS/compiler/kernel/etc. issue.
static char buffer[BUF_TINY];
You allocate a buffer of 64 bytes, but it's irrelevant since there's a separate 'len' parameter on which the assertion happens, and this 'len' parameter contains a much smaller number.
comment:109 follow-up: ↓ 112 Changed 8 years ago by michael-o
Replying to egmont:
(Disclaimer: I'm writing this comment without looking at the code.)
I feel too much confusion...
You add 3 because... why 3? Sounds like you're expecting every character of "MiB" and friends to be transcribed to let's say Russian. How about CJK (3 bytes per character), Vietnamese (they use a lot of combining character as far as I know) etc. scripts? How do you know that they don't need more?
I don't. It was a base assumption that two bytes per char would suffice, but this is far from complete.
The code, without a comment right there about this "+ 3" IMO cannot be understood.
Actually, I did in the Git commit bae814d0d48dbb8eae48231f13e8aaec544178d8 but obviously this was not enough. Granted.
You previously called this 'len', add 3, and still call it 'len'. This is a very bad concept. Mandatory read: http://www.joelonsoftware.com/articles/Wrong.html.
The two most important concepts needed in mc are the length in bytes when encoded in UTF-8 (usually called 'len' or 'length') and the width it occupies on the screen aka. the number of cells (usually called 'width'). They are quite loosely coupled: a Unicode codepoint can take anywhere from 1 to 4 bytes in UTF-8, and can occupy anywhere from 0 to 2 character cells.
Exactly! This was my primary problem with the columns. panel_fields[] in panel.c passes byte length which made my addition necessary. Throughout the code only length semantic is used where widths would be necessary. That would require to change several other spots of the code when some multibyte locale is used.
In the spirit of the aforementioned article, if you add 3 because of the UTF-8 encoding as well as varying display width of characters (and if this is indeed the right way of doing the maths which I really doubt) then the variable should be called 'width' before incrementing, and 'len' afterwards.
Don't forget that this 'width' directly influences column sizes and if you pass lengh=width*4 to accomondate all possible sizes, it will directly influence the number of digits displayed for the input.
Now, I think I would probably get rid of passing 'len' (the buffer length in bytes) across these methods. It usually makes sense if the data to be stored there can be arbitrarily large (or quite large) and you don't always want to entirely store it. This is not the case here. The "tiny" bufsize (64) is a safe upper limit, a file size suffixed by units will always fit in all locales (or if not because of non-latin digits for some locale, we can just increase the tiny bufsize). I think it's okay to say in all these methods that the caller is expected to give a large enough buffer that can store the output, and make the code simpler by not communicating the actual buffer size. There's absolutely no point in trying to save a couple of bytes by allocating smaller buffers.
In some spots, the buffer is not only used for the size, but for other strings as well. Size cannot be indefinitely large.
As for formatting for a given available width on the screen, there are two possible approaches I can imagine, and I'd need to check the code to see which one it does.
One possibility is that the method that formats the number doesn't care about the width, and it's the caller that somehow truncates it afterwards if it turns out to be too wide. I guess this approach is okay, although not as flexible as the other.
The other possibility is that the method that formats the number knows the available width. As such, in this case this method needs to know the 'width' as a parameter, rather than 'len', which is something that being incremented by 3 because of UTF-8 just when calling this method is obviously totally wrong.
I hope this comment helps coming up with a cleaner design and implementation. Thanks guys for working on this! :)
It is likely that panel_field_t needs to extended to accomondate all possible Unicode points in the manner you had in mind.
Anyway, thank you very much for the valueable input. I am open to any improvement/new approach in my code.
comment:110 Changed 8 years ago by michael-o
Here is the output of GDB (core dump) on RHEL 6:
Program terminated with signal 11, Segmentation fault.
#0 0x000000000044ce35 in size_trunc_len (buffer=0x6de100 "~B", len=6, size=96, units=0, use_si=0)
at util.c:515
515 if (size < power10[len - (1 + 6)])
Missing separate debuginfos, use: debuginfo-install glib2-2.28.8-5.el6.x86_64 glibc-2.12-1.192.el6.x86_64 ncurses-libs-5.7-4.20090207.el6.x86_64
(gdb)
(gdb) where
#0 0x000000000044ce35 in size_trunc_len (buffer=0x6de100 "~B", len=6, size=96, units=0, use_si=0)
at util.c:515
#1 0x0000000000435da4 in string_file_size (fe=<value optimized out>, len=<value optimized out>)
at panel.c:518
#2 0x00000000004332ee in format_file (panel=0xab0c10, file_index=<value optimized out>, mv=1, attr=
0, isstatus=0) at panel.c:819
#3 repaint_file (panel=0xab0c10, file_index=<value optimized out>, mv=1, attr=0, isstatus=0)
at panel.c:944
#4 0x00000000004338c9 in paint_dir (panel=0xab0c10) at panel.c:1060
#5 0x000000000043859f in panel_callback (w=0xab0c10, sender=<value optimized out>,
msg=<value optimized out>, parm=<value optimized out>, data=<value optimized out>)
at panel.c:3658
#6 0x000000000042bdcb in setup_panels () at layout.c:756
#7 0x0000000000431725 in midnight_callback (w=<value optimized out>, sender=<value optimized out>,
msg=<value optimized out>, parm=<value optimized out>, data=<value optimized out>)
at midnight.c:1430
#8 0x000000333a63db5c in g_list_foreach () from /lib64/libglib-2.0.so.0
#9 0x0000000000417767 in dialog_change_screen_size () at dialog-switch.c:381
#10 0x0000000000419455 in frontend_dlg_run (h=0xaa1ca0) at dialog.c:520
#11 dlg_run (h=0xaa1ca0) at dialog.c:1196
#12 0x0000000000430a13 in create_panels_and_run_mc () at midnight.c:954
#13 do_nc () at midnight.c:1770
#14 0x000000000040dd0c in main (argc=1, argv=0x7ffd75b83e38) at main.c:403
comment:111 in reply to: ↑ 108 Changed 8 years ago by michael-o
Replying to egmont:
static char buffer[BUF_TINY];You allocate a buffer of 64 bytes, but it's irrelevant since there's a separate 'len' parameter on which the assertion happens, and this 'len' parameter contains a much smaller number.
Just checked the code. Without knowing a lot of the internal mechanics of mc, I assumed that the panel_field_t.min_size is really a hard min size and never less and this is what I used throughout. It obviously isn't. Unless someone know why, I would accept Andrew's offer from comment:91.
comment:112 in reply to: ↑ 109 Changed 8 years ago by egmont
Replying to michael-o:
Guys, I'm really not happy to say this, but I'm getting seriously concerned. Two segfaults, the author apparently not being experienced enough in C string handling, crazily mixing the semantics, try-and-error approach (randomly changing the code until it doesn't seem to crash, rather than properly designing and implementing it), blaming it on Linux... this just doesn't look good to me at all.
Actually, I did in the Git commit bae814d0d48dbb8eae48231f13e8aaec544178d8 but obviously this was not enough. Granted.
Having a version control log is obviously a must-have in software development but it shouldn't be the primary source of documentation. The code itself (e.g. in the tarball) should be understandable, or wherever it gets trickier, it should contain at least a pointer to the explanation.
Exactly! This was my primary problem with the columns. panel_fields[] in panel.c passes byte length which made my addition necessary. Throughout the code only length semantic is used where widths would be necessary. That would require to change several other spots of the code when some multibyte locale is used.
mc is legacy code (22 years old, with UTF-8 support being pretty new compared to that). I don't know who implemented UTF-8 support (truly sorry for that, great kudos!), it was a really tough work, and done greatly. It's sure not picture perfect and sure doesn't look like as if mc's been implemented with UTF-8 straight from the beginning. I vaguely recall that I myself have filed a ticket (probably still open) about clarifying the terminology and renaming some variables (e.g. 'len' vs 'width'). That being said, in the existing code it's still quite easy to figure out the meaning wherever a variable is incorrectly named, and I really don't think there are codes along "len += 3" to convert from length to width. Also, new code should preferably be written with the proper terminology.
Don't forget that this 'width' directly influences column sizes and if you pass lengh=width*4 to accomondate all possible sizes, it will directly influence the number of digits displayed for the input. [...snip...]
At this point I totally don't understand what you say (and probably you don't understand either what I said in my previous comment). And it feels to me that you try to justify the behavior by bringing up the current (buggy) implementation as how the behavior should be.
I have no clue what you mean by "this 'width' directly influences column sizes". In mc the width of a formatted string doesn't influence anything. It's the other way around: the width needs to obey the available column count.
I'm also absolutely lost at "length=width*4" which is just as bad as the "+3" was.
In your thinking, the caller goes like: "I've allocated a buffer of 64 bytes. I need to have the size formatted in (let's say) 8 character cells and placed here. I believe that the UTF-8 overhead will be no more than 3 bytes, even despite that noone will revise my code when the formatter method changes, or when a translation is updated. So let's pass 8+3 = 11 as the length/width (whatever) to the formatter method, even if the current locale is English". Terribly wrong! And for that matter, passing 4*8 = 32 or anything similar would be just as wrong too.
Do you want to tell the formatter method how many bytes it can safely write without risking a segfault? If so, tell it 64 (and call that parameter 'length').
Do you want to tell it how many visual cells are available for the formatted string? If so, tell it 8 (and call that parameter 'width').
There's absolutely no way that could justify passing it 11 or 32 or anything different.
So, again, there are two absolutely totally utterly independent stories:
- How does the formatter method know how much storage space is available? Some possible answers:
- Require that the caller allocates an obviously large enough buffer, maybe 64 bytes or so, and don't care about this any more.
- Require that the caller tells us the available storage space, and if and only if we would write beyond that, the formatter method bails out with an error and then the caller allocates a larger buffer and tries again. Very complex to implement for no benefit. Mostly used in system calls (see e.g. readline(2)) because the kernel cannot allocate new memory for the user. I firmly vote against this approach in mc.
- The formatter method dynamically allocates a large enough new string.
- Some higher level object (e.g. GString) is used.
And, totally independently from this:
- How does the formatter know the required width?
- It does not. The caller checks the width of the formatted string and if it's too wide, it truncates. The truncation probably automatically happens with the (~) symbol in the middle. It's consistent across the UI, although not quite flexible and the data shown there is not as informative as it could be.
- It's passed on as an argument. The formatting method is allowed to take this into account in various ways, e.g. omitting some decimals or omitting the space in front of the unit if width is too small.
Independently from each other, pick one possible answer for both questions, and then implement the formatting method according to this interface. Let 'len' always mean the length in bytes, and 'width' always be the available visual width, and never ever ever have a variable that's a bit of this and a bit of that.
It is likely that panel_field_t needs to extended to accomondate all possible Unicode points in the manner you had in mind.
I've no clue about panel_field_t, however, apparently (see the mcview segfault earlier on) the formatter is used at other places as well, not just in the panel.
After a failed attempt, I became firm on the opinion that the formatter shouldn't make any assumptions on where/how the formatted string would be used, what'll be the minimum width etc.
comment:113 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
Exactly! This was my primary problem with the columns. panel_fields[] in panel.c passes byte length which made my addition necessary. Throughout the code only length semantic is used where widths would be necessary. That would require to change several other spots of the code when some multibyte locale is used.
Don't forget that this 'width' directly influences column sizes and if you pass lengh=width*4 to accomondate all possible sizes, it will directly influence the number of digits displayed for the input. [...snip...]
At this point I totally don't understand what you say (and probably you don't understand either what I said in my previous comment). And it feels to me that you try to justify the behavior by bringing up the current (buggy) implementation as how the behavior should be.
I have no clue what you mean by "this 'width' directly influences column sizes". In mc the width of a formatted string doesn't influence anything. It's the other way around: the width needs to obey the available column count.
I'm also absolutely lost at "length=width*4" which is just as bad as the "+3" was.
In your thinking, the caller goes like: "I've allocated a buffer of 64 bytes. I need to have the size formatted in (let's say) 8 character cells and placed here. I believe that the UTF-8 overhead will be no more than 3 bytes, even despite that noone will revise my code when the formatter method changes, or when a translation is updated. So let's pass 8+3 = 11 as the length/width (whatever) to the formatter method, even if the current locale is English". Terribly wrong! And for that matter, passing 4*8 = 32 or anything similar would be just as wrong too.
Do you want to tell the formatter method how many bytes it can safely write without risking a segfault? If so, tell it 64 (and call that parameter 'length').
Do you want to tell it how many visual cells are available for the formatted string? If so, tell it 8 (and call that parameter 'width').
The whole point about length=width*4 was the semantic mismatch between byte and character orientation I was trying to tell you about. If you want to fill n width in a column, you are talking about characters but length in the context of mc operates on bytes.
In the very special case of size_trunc_len() and alike is that the passed len is given in bytes but the upper-level in panel_fields[] contains length in bytes but expects it to be columns. More than that, the scale logic in again byte/single byte char oriented and limited by length. If you pass a buffer with 64 byte and say length=64, it will never scale numbers down to KiB, MiB, etc. because there is enough space (given by length) to accomodate that. You'd always need calculate wether your Unicode points fit in the given length based on the UTF-8 encoding scheme.
It may be a limitation in mc existed ever since, as you mention it is 22 years old, but now revealed simply by my changes. The caller does not know upfront how many bytes the characters will consume. That's the crux -- at least for me.
comment:114 Changed 8 years ago by egmont
Replying to michael-o:
The whole point about length=width*4 was the semantic mismatch between byte and character orientation I was trying to tell you about. If you want to fill n width in a column, you are talking about characters but length in the context of mc operates on bytes.
Even as an upper limit this would be incorrect because of combining characters. It might take even more than 'width*4' UTF-8 bytes to produce a string of width 'width'.
In the very special case of size_trunc_len() and alike is that the passed len is given in bytes
What's the semantics of len here? Is it the number of available bytes in the output buffer, or is it the number of desired bytes to fill it up with? You're mixing the two! When thinking in bytes, the number of available bytes is 64 in the current code, whereas the number of desired (or maximum) bytes to which to format the string does not make sense. Why would you want to ask the formatter "hey format me this number, I give you a quite large buffer, but make sure not to write more than 11 bytes"? No sense whatsoever. It's the desired UI look you care about, in some locales it'll take 8 bytes, in some it'll take 11, in some it'll take even more. The formatter will know this, why should the caller care? If you specify a limit in bytes, it should be because of technical limitation (the buffer being finite long).
Whereas, on the other hand, you might want to ask the same questions for width. Here, the concept of available width in the buffer does not make any sense, whereas the desired width, to which to format the string (which is 8 in my recent example), is an important one.
You need to absolutely cleary separate all these conceps in your mind. Currently you're thiking about a washed-up mess of these. As long as you don't manage to separate these concepts, you won't be able to come up with proper code.
My fridge is able to store maybe 40-60 cans of beer. Dunno. Depends on the sizes of the cans. But still, I can ask my friend to bring only 6 cans. Why would I have to lie that my fridge is only able to store 6 cans?
but the upper-level in panel_fields[] contains length in bytes but expects it to be columns. More than that, the scale logic in again byte/single byte char oriented and limited by length.
Again, you're bringing up the current buggy code as the rationale for the code being buggy.
If you pass a buffer with 64 byte and say length=64, it will never scale numbers down to KiB, MiB, etc. because there is enough space (given by length) to accomodate that.
It will (if implemented properly) because the semantics of the length parameter is not the desired length of the output, but the technical maximum allowed.
The caller does not know upfront how many bytes the characters will be consume. That's the crux -- at least for me.
This is something anyone ever doing UTF-8 coding needs to overcome. In this case it's damn simple (if going for the "a" answer for the 1st question in my previous comment): just pass it an obviously big enough buffer and don't care about it anymore.
comment:115 follow-up: ↓ 116 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
The whole point about length=width*4 was the semantic mismatch between byte and character orientation I was trying to tell you about. If you want to fill n width in a column, you are talking about characters but length in the context of mc operates on bytes.
Even as an upper limit this would be incorrect because of combining characters. It might take even more than 'width*4' UTF-8 bytes to produce a string of width 'width'.
In the very special case of size_trunc_len() and alike is that the passed len is given in bytes
What's the semantics of len here? Is it the number of available bytes in the output buffer, or is it the number of desired bytes to fill it up with? You're mixing the two! When thinking in bytes, the number of available bytes is 64 in the current code, whereas the number of desired (or maximum) bytes to which to format the string does not make sense. Why would you want to ask the formatter "hey format me this number, I give use a quite large buffer, but make sure not to write more than 11 bytes"? No sense whatsoever. It's the desired UI look you care about, in some locales it'll take 8 bytes, in some it'll take 11, in some it'll take even more. The formatter will know this, why should the caller care? If you specify a limit in bytes, it should be because of technical limitation (the buffer being finite long).
This is the desired amount of bytes, upper bound. I am not mixing it. I was aware of this issue upfront and this existed way before I started to change anything. The reason for limit the output length is that the column is bound to 8 chars, everything is truncated with a tidle. Not my contribution. That's the current state.
You need to absolutely cleary separate all these conceps in your mind. Currently you're thiking about a washed-up mess of these. As long as you don't manage to separate these concepts, you won't be able to come up with proper code.
This is a general problem in the entire codebase I cannot solve.
My fridge is able to store maybe 40-60 cans of beer. Dunno. Depends on the sizes of the cans. But still, I can ask my friend to bring only 6 cans. Why would I have to lie that my fridge is only able to store 6 cans?
Without knowning the volume of your fridge and the cans, this question is impossible to answer. Therefore, I prefer wine, standard 750 mL by volume.
but the upper-level in panel_fields[] contains length in bytes but expects it to be columns. More than that, the scale logic in again byte/single byte char oriented and limited by length.
Again, you're bringing up the current buggy code as the rationale for the code being buggy.
If you pass a buffer with 64 byte and say length=64, it will never scale numbers down to KiB, MiB, etc. because there is enough space (given by length) to accomodate that.
It will (if implemented properly) because the semantics of the length parameter is not the desired length of the output, but the technical maximum allowed.
The caller does not know upfront how many bytes the characters will be consume. That's the crux -- at least for me.
This is something anyone ever doing UTF-8 coding needs to overcome. In this case it's damn simple (if going for the "a" answer for the 1st question in my previous comment): just pass it an obviously big enough buffer and don't care about it anymore.
With my little knowledge of the codebase, I am not in the position to properly evaluate this option.
comment:116 in reply to: ↑ 115 Changed 8 years ago by egmont
Replying to michael-o:
What's the semantics of len here?
This is the desired amount of bytes, upper bound.
I have just explained to you why this concept does not make any sense whatsoever. (And by the way, I have also just clarified that I used 'len' with the other semantics, the one that does make sense.)
The reason for limit the output length is that the column is bound to 8 chars, everything is truncated with a tidle.
And as such the output should be limited to a certain number of character width, which has not much to do with the length in bytes.
Not my contribution. That's the current state.
I'm afraid you're far from understanding how mc works. The problem of displaying data in a certain width is solved throughout mc without segfaults and such.
I feel like this discussion is going nowhere, and as much as I'd love to spend much time on mc (including reviewing the patches here, fixing the code etc.), I hardly have any. As such, the top priority for me remains speaking up when I'm afraid things are going wrong... and that's why unfortunately I'm here.
Seeing the history of this ticket, the problems encountered on the way, the two segfaults, your uncertainity in C string handling, the antipatterns and unclear semantics of variables, the terrible "+3" hack for UTF-8, you yourself being in serious doubts why the code fails, and so on, I believe that this patch is noticably below the average quality of mc. Even worse than that: you seem to be stubborn that you're doing things okay, you're not listening to me how it should be done, and blame the rest of the codebase.
If any of the developers here are willing to give this patchset a really thorough review/cleanup and heavy stress-testing (including (fake) translations to Russian, some CJK, and a language with lots of combining chars), let it be. Otherwise my vote for goes for reverting it entirely. In its current form it doesn't bring the quality that I could be happy about, could be rest calm without worrying about a third segfault being discovered by someone shortly after the release of the next tarball... :(
I'm sorry but I don't have time (nor motivation) to continue the discussion we had in the last couple of comments.
comment:117 follow-up: ↓ 118 Changed 8 years ago by michael-o
Replying to egmont:
Replying to michael-o:
What's the semantics of len here?
This is the desired amount of bytes, upper bound.
I have just explained to you why this concept does not make any sense whatsoever. (And by the way, I have also just clarified that I used 'len' with the other semantics, the one that does make sense.)
Either I do not understand you or you don't understand me. You are either implying that I have introduced this concept or have abused it. The former is not true, the latter arguable. I have simply reused what was given w/o reinventing the wheel.
The reason for limit the output length is that the column is bound to 8 chars, everything is truncated with a tidle.
And as such the output should be limited to a certain number of character width, which has not much to do with the length in bytes.
Why don't you show a simple patch where you depict your idea as you imply that I don't get it?
Not my contribution. That's the current state.
I'm afraid you're far from understanding how mc works. The problem of displaying data in a certain width is solved throughtout mc without segfaults and such.
This is maybe true, but I have to start somewhere...
Seeing the history of this ticket, the problems encountered on the way, the two segfaults, your uncertainity in C string handling, the antipatterns and unclear semantics of variables, the terrible "+3" hack for UTF-8, you yourself being in serious doubts why the code fails, and so on, I believe that this patch is noticably below the average quality of mc. Even worse than that: you seem to be stubborn that you're doing things okay, you're not listening to me how it should be done, and blame the rest of the codebase.
If I would be stubborn, I wouldn't take any discussion trying to sort things out and understand what you are really after. I never said that the things I do are best, I even admitted that I am *not* a day-to-day C hacker several times. Again, it would be very benificial showing a snippet of code to portray your idea.
You had plenty of time to evaluate my patches and reject them, so that I can learn and improve.
comment:118 in reply to: ↑ 117 Changed 8 years ago by egmont
Replying to michael-o:
Why don't you show a simple patch where you depict your idea as you imply that I don't get it?
If you do not understand my written description how I'd go with the code, I'm sorry but I don't trust you that you'd be able to properly finish a started proof of concept patch. And I don't have time (let alone motivation since I didn't agree with the goal of this patch from the beginning) to come up with a complete polished and well-tested patch.
You had plenty of time to evaluate my patches and reject them, so that I can learn and improve.
I did not have free time to work on this. I trusted that it went in the right way; it turned out just recently that it didn't and it's not even close to that.
I understand it sucks from your point of view that someone comes along and criticizes your work without contributing a single line of code to it. But let's be honest: I'm here because it crashes, and after realizing that, I found a no-go in the code and then found other no-gos during our discussions. I have time to speak up that something's horribly wrong here, whereas I don't have time to fix it, sorry.
comment:119 Changed 8 years ago by egmont
I took a closer look at the actual behavior. In the examples below I'll substitute spaces by underscores so that the formatting remains correct.
A size that is __4096_B on 8 characters becomes __4_KiB on 7 columns. Why the change if the previous formatting would still fit?
A size of __600_B on 7 columns becomes _1_KiB on 6 columns. Same story I guess.
A size of __400_B on 7 columns becomes ____~B on 6 columns. Very bad.
Similarly, __40_B becomes ___~B on 5 columns, and __4_B becomes __~B on 4 columns, although _0_B remains untruncated on 4 columns.
comment:120 follow-up: ↓ 121 Changed 8 years ago by andrew_b
- Status changed from closed to reopened
- Votes for changeset committed-master deleted
- Resolution fixed deleted
- Branch state changed from merged to no branch
Since I took the ownership of this ticket, all regressions are my fault.
I'm going to revert commits that introduced segfaults and start to implement this topic with small steps.
comment:121 in reply to: ↑ 120 Changed 8 years ago by michael-o
Replying to andrew_b:
Since I took the ownership of this ticket, all regressions are my fault.
I'm going to revert commits that introduced segfaults and start to implement this topic with small steps.
Fair enough. If you need any kind of assistance, please let me know.
comment:122 Changed 8 years ago by egmont
Thanks very much to both of you!
comment:123 Changed 8 years ago by andrew_b
So, I have some more or less working version.
Branch: 3666_iec_si_prefixes_2
Initial changeset:fdd9ab4098124d94967e7fede7d885ab59e1a09b
comment:124 follow-up: ↓ 125 Changed 8 years ago by zaytsev
egmont, michael-o?
comment:125 in reply to: ↑ 124 Changed 8 years ago by michael-o
Replying to zaytsev:
egmont, michael-o?
I will have a look next week and let you know. Haven't had the time since.
comment:126 Changed 8 years ago by zaytsev
Anything new?
comment:127 follow-up: ↓ 128 Changed 8 years ago by zaytsev
michael-o?
comment:128 in reply to: ↑ 127 Changed 8 years ago by michael-o
comment:130 Changed 8 years ago by zaytsev
michael-o: and...? I mean, really...
comment:131 follow-ups: ↓ 132 ↓ 133 Changed 8 years ago by zaytsev
- Cc mooffie added
andrew_b, mooffie, egmont: I suggest the following - I will make an rc this weekend, without this branch, and we will see if we merge it after the release. The skins are now committed, quite some stuff has accumulated in the NEWS file and last release was in fall. I think we should really make one now. What do you think?
comment:132 in reply to: ↑ 131 Changed 8 years ago by michael-o
Replying to zaytsev:
andrew_b, mooffie, egmont: I suggest the following - I will make an rc this weekend, without this branch, and we will see if we merge it after the release. The skins are now committed, quite some stuff has accumulated in the NEWS file and last release was in fall. I think we should really make one now. What do you think?
Please go ahead with your RC and don't wait for me! Other annoying issues at work held me off doing a verification of the branch.
comment:133 in reply to: ↑ 131 Changed 8 years ago by egmont
Replying to zaytsev:
I will make an rc this weekend, without this branch
I agree. This one's a controversial change, and hasn't quite been tested in git master. Let's not commit it last minute before a release, let's stay safe instead (and commit soon after a release, if it's believed to be production ready).
comment:135 follow-up: ↓ 136 Changed 8 years ago by zaytsev
michael-o, are you still alive?
comment:136 in reply to: ↑ 135 Changed 8 years ago by michael-o
Replying to zaytsev:
michael-o, are you still alive?
Partially, fighting with angina and 38° fever...
comment:137 Changed 7 years ago by zaytsev
Ping.
comment:138 Changed 7 years ago by zaytsev
- Milestone changed from 4.8.20 to 4.8.21
No reaction from submitter...
comment:139 Changed 6 years ago by zaytsev
- Milestone changed from 4.8.21 to 4.8.22
No reaction from submitter...
GitHub? branch: https://github.com/michael-o/mc/tree/ticket-3666
Git patch attached.